
GitOps using Flux and Flagger

GitOps as a practice has been in use since 2017 when Alexis Richardson coined the term. It transformed DevOps and automation. If you look at its core principles, it extends DevOps by treating Infrastructure as Code (IaC). Your deployment configuration is stored in a version control system (a.ka. Git), providing a single source of truth for both dev and ops.
As the framework’s adoption increased, GitOps became the standard for continuous deployment in the cloud native space. Many agile teams adopt GitOps because of familiarity with git-based workflow for release management of cloud native workloads.
GitOps principles differ from the traditional CI & CD pipeline approach. In the last few years, the GitOps working group under CNCF formalized all the ideas developed around GitOps into a cohesive set of principles that have become the GitOps Principles.
- Declarative
- Versioned and Immutable
- Pulled automatically
- Continuously Reconciled
The uses of GitOps helped organizations in the following aspects:
- Swifter deployment and more often
- Fast and easy disaster recovery
- Effortless credential management
- Improved developer experience
GitOps created a standard practice that allowed engineers to focus on developing solutions rather than figuring out how to deploy them.
However, as companies grow, they increase the rate of new features, and the risk of downtime/failures in production also increases. They face problems like the control of blast radius and minimal risk from recent releases.
So, is there any way blast radius can be minimized while testing out releases to a subset of users? – Yes, there is a way through Progressive Delivery.
Progressive Delivery
What is Progressive Delivery and who coined the term? The term Progressive Delivery was coined by James Governor at RedMonk, who talked about new software development practices beyond continuous delivery. Based on James Governor’s transcript on Progressive Delivery, we want to minimize the blast radius and control the delivery. This could be done by diverting some traffic to new deployment, measuring the success metrics, and then promoting the release to all users. Some of deployment strategies are Canary, Blue-Green, and A&B testing.
There are a lot of tools that allow us to implement progressive delivery. Azure DevOps, AWS App Mesh are the widely used proprietary tools, while ArgoCD and Flux are widely used open source tools. In this blog post, we shall focus on Flux & Flagger, which is an open source tool that is quite popular.
What is Flux? Flux is a tool for keeping Kubernetes clusters in sync with sources of configuration (like Git repositories) and automating updates to the configuration when there is new code to deploy.
What is Flagger? Flagger is a Progressive Delivery tool that automates the release process for applications running on Kubernetes. Under the hood, both tools are built on top of a modular GitOps toolkit. It is the main reason why Flagger compliments Flux.
Typical Pipeline
Let’s level-set how a CI/CD pipeline works, then we can talk about how Flux and Flagger fit in the picture.
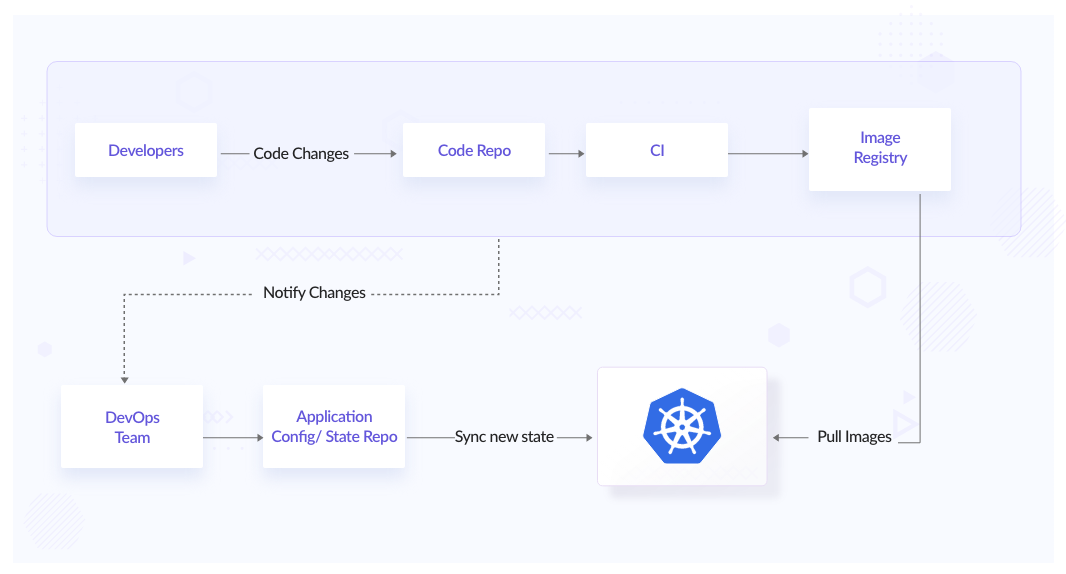
In a typical CI/CD pipeline, we push the latest images to the registry and config changes to a repository. Hereon the Ops person will correct the cluster state with the new config changes by applying a new config or upgrading the existing resources in the Kubernetes cluster. This also typically means that the ops person should know the changes that need to be made along with the context of those changes, and hence this manual process quickly becomes error-prone.
This whole process also becomes time-consuming and hard to manage. There can be issues that might occur after applying the latest changes. We need to have a solid & spontaneous feedback loop on new releases.
What if we could automate the whole process from deployment to production and have proper change management in place for application & infra configuration? Here comes Flux, which helps us automate image tag updates to git and reconciliation of clusters to the desired state as soon as new changes are pushed to the git repository.
Flux
Let’s put Flux in place to see how we resolve all those issues from a typical pipeline.
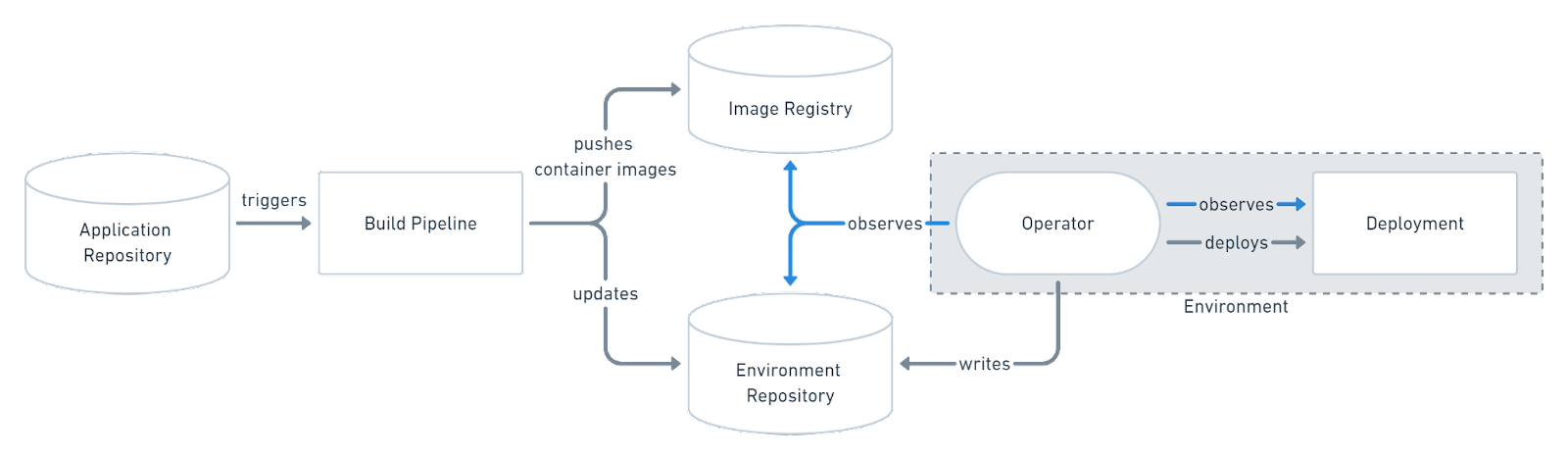
Source: GitOps
Flux is based on the Operator pattern. Operator pattern is software extension to Kubernetes that uses custom resources to manage application components is built on top of Kubernetes API.
Installation of Flux
Installation of Flux is straightforward. You need to install Flux CLI to run the bootstrapping process. The bootstrapping process will create a repository on GitHub (or any other git hosting service) and all required manifests for installation and connection to the git repository. Follow this doc to Get started with Flux.
Reconciliation
Flux keeps a constant watch on the changes in your repository. It doesn’t require any event to start the reconciliation loop. It allows you to configure the reconciliation loop at each component. You can have your git checked every 3 minutes and sync in 10 min, allowing you to stagger how reconciliation happens.
Automate image updates to Git
When Flux comes into the picture, it will start watching your image registry for new updates and push back to git for you. We don’t have to take care of updating the image IDs this time. This feature is not enabled while setting up the Flux. You can follow this Automate image update to Git - Flux.
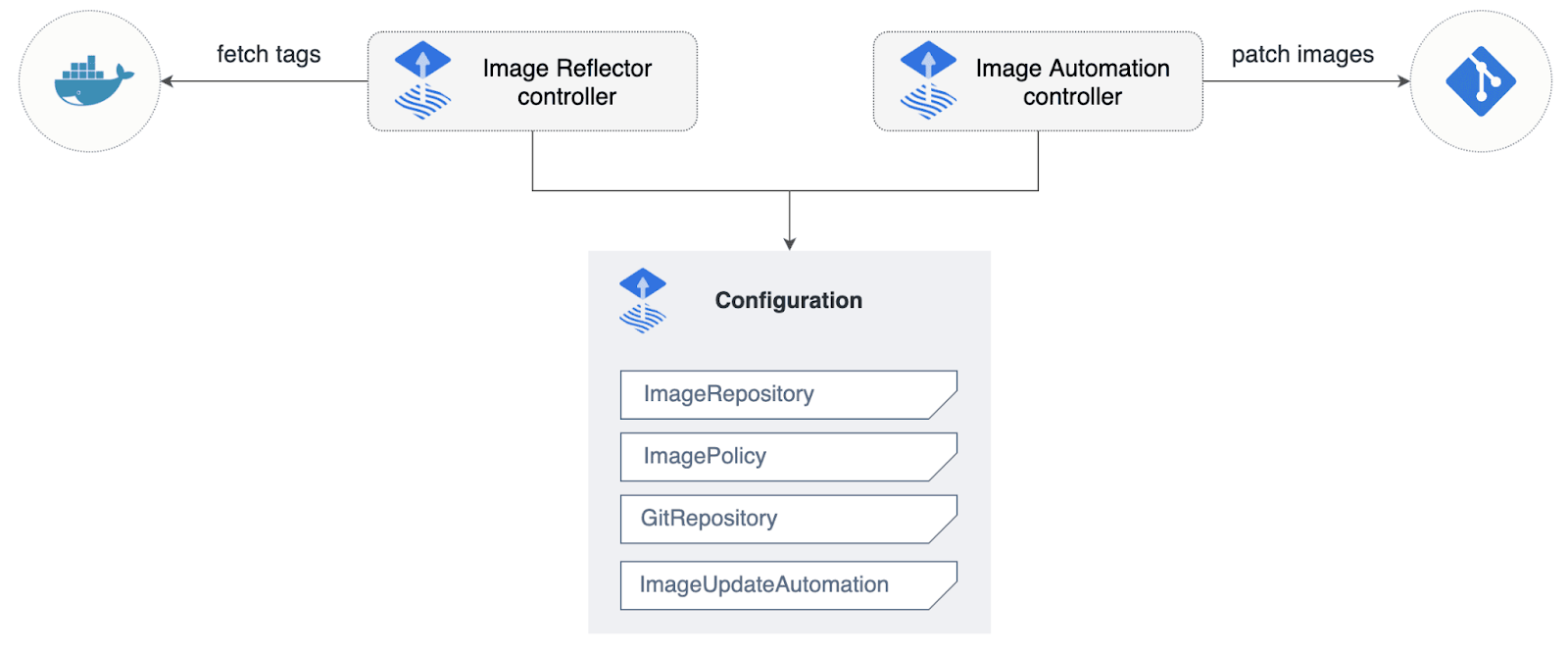
Secret Management
Once you adopt GitOps, you need to find a way to manage the secrets that your application might require to communicate to other services within the Kubernetes cluster. You can’t simply store your application secrets inside the git repository, right? You might be thinking of different ways of encryption. For example, you can commit secrets to version control and enable Flux to decrypt them.
Flux provides two guides to store secrets through Sealed Secrets and Mozilla SOPS.
Application Delivery
Unlike other options Flux natively supports Helm and uses native Helm library to deploy helm release onto the cluster. This means you can run helm ls on a cluster and it will show exactly how helm install works.
Another important thing is Flux allows you to manage dependencies between HelmRelease CRDs or Kustomization CRDs. It enables you to control the load order of collections/groups of YAML files. It does not maintain the order in which individual YAML files are applied.
Promote Release
Flux can help you automate the process of promoting the release with GitHub Actions.
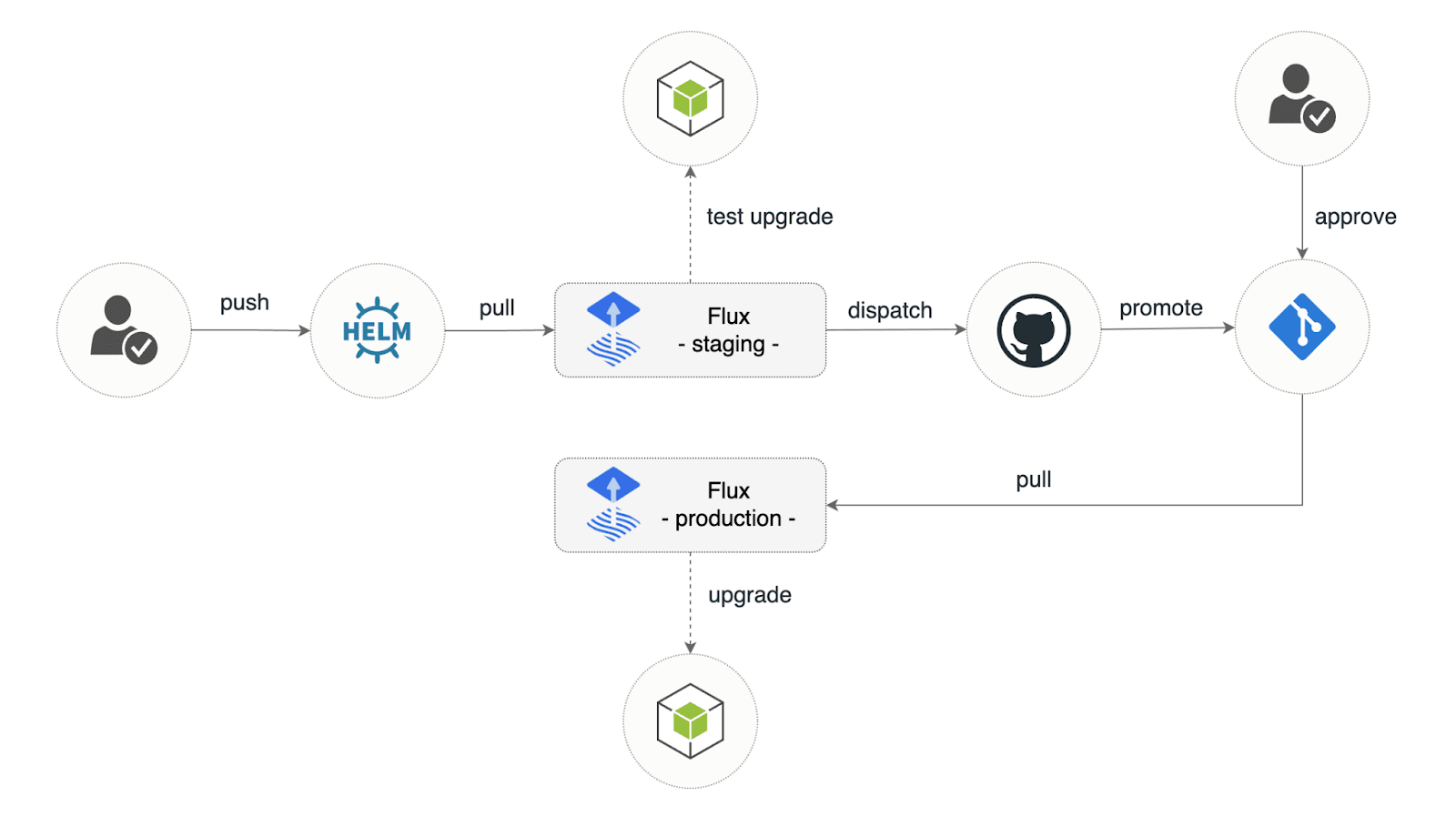
Webhooks
Flux is, by design pull-based (i.e, identifies the changes directly from the source ) and good at managing drift in clusters because it is easier to correct the state of a cluster from inside rather than from outside where your tool doesn’t have a correct understanding of the current state of clusters.
Suppose you want to make your pipeline responsive as a push-based or faster process. In that case, you can set up webhook receivers on git push that will trigger reconciliation.
Alerting and notifications
Flux can notify you about the resource statuses change as the health of the new app’s version. You can receive alerts about reconciliation failure in clusters and configure different mediums for reporting - channels such as Slack or embedded in git commit status. This helps inform the developer team whether the new version of the app was deployed and whether it is healthy or not.

Source: Flux Slack Error Alerts

Source: Setup Notifications | Flux
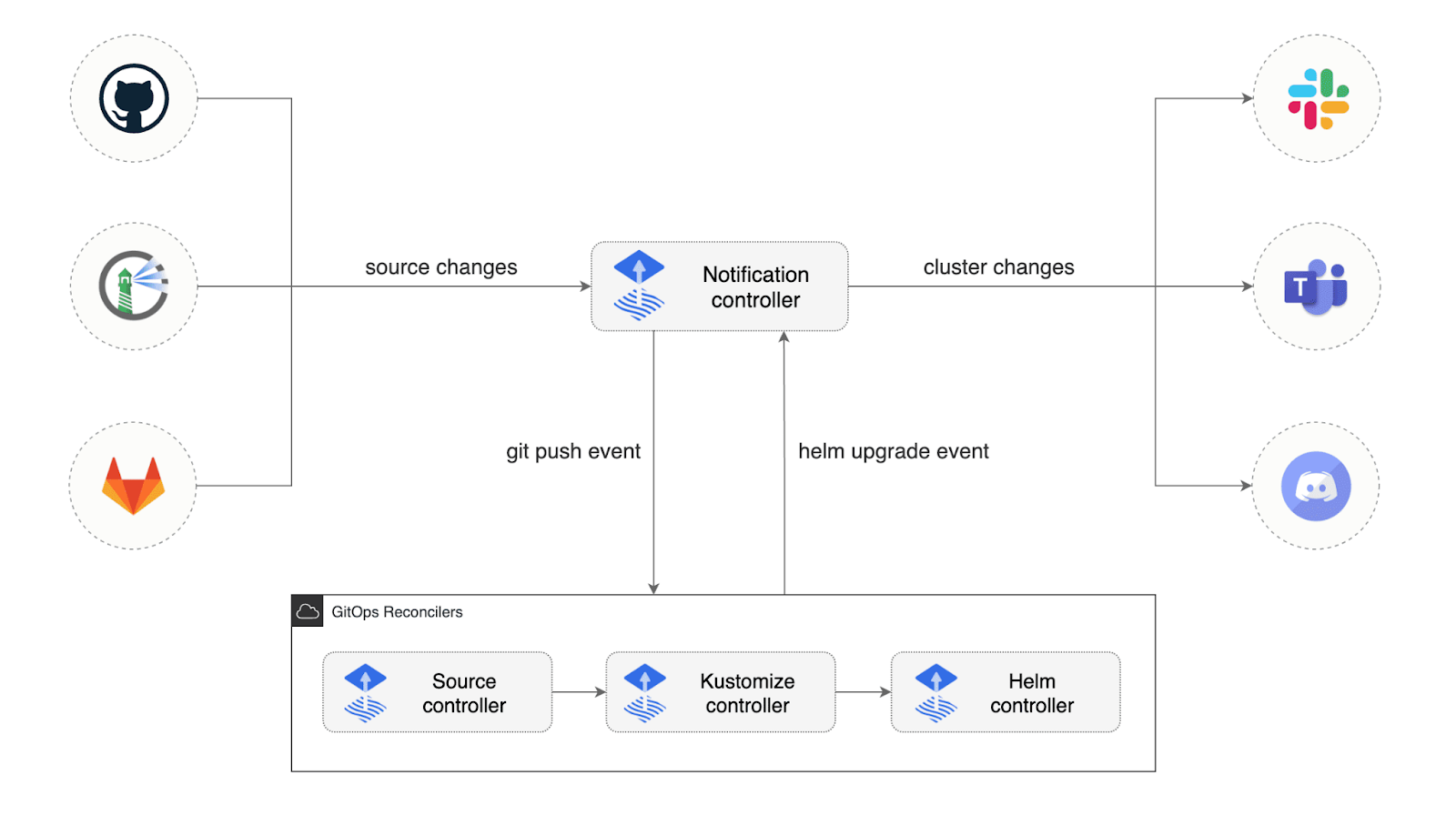
Source: Notification Controller | Flux
Authorization Methods
Flux relies on the RBAC capabilities of Kubernetes and does not have its own authorization management. It uses Kubernetes RBAC for authentication or authorization. It can be a downside if you want to provide authorization using SSO.
User Interface
There is no UI for Flux. It does have an experimental UI that is not in an active development state at the time of writing this.
Flagger
So far, we have automated our delivery process to the cluster with alerts and notifications in case of any failure and unhealthy state of the cluster. Now, we will look at how Flagger integrates into this process and allows different deployment strategies. How Flagger helps in Progressive Delivery.
With the best alerting and notification in place, we are not resilient to downtime due to new releases. How can we be sure of our mission-critical services work as expected? A bad release can cause colossal business value loss. For example, your team might want to test a new feature on a small sample of users, and if that feature performs well, it will be rolled out to all users.
In order to do that without causing any hindrance to day-to-day activities. Flagger lets us automate the release process and reduces the risk of introducing a new release in production by gradually shifting traffic to the new release while measuring metrics and running conformance tests.
Example of Progressive Delivery with Flagger.
Configuration
Flagger is compatible with any CI/CD solutions, so it can be used with Flux, Jenkins, Carvel, Argo, etc. It supports various service mesh like App Mesh, Istio, Linkerd, Kuma, Open Service Mesh, or an ingress controller like Contour, Gloo, NGINX, Skipper, and Traefik. It has excellent compatibility with Linkerd and it’s reasonably easy to get started with canary release and metrics analysis.
One of the important factors that come into the picture sometime i.e., Flagger doesn’t require replacing Deployment objects with any custom type.
Deployment Strategies
Flagger implements several deployment strategies which help you achieve the same objective which is shifting traffic gradually to a new version of the release. Some of the strategies are:
- Canary Releases
- A/B Testing
- Blue/Green Mirroring
- Blue/Green
Check out Flux CD official docs to know more about deployment strategies.
Metrics
Flagger comes with built-in metrics and a Grafana dashboard for canary analysis. It exposes Prometheus metrics to dig more into the canary analysis. You can create custom metrics that can be used to do metrics analysis for release.
That’s the beauty of it once Flagger validates service level objects like response time and any other metrics specific to the app, it promotes the release otherwise, it will be automatically rolled back with minimum impact to end-users. We’re not diving into the details of how the metrics template can be used in the analysis step.
Manual Gating
Not just metrics-based approval, you can perform manual gating to have more control over your canary analysis. There are different kinds of webhooks that you can leverage at each step of canary analysis, for example, confirm-rollout and conform-promotion. A flagger will halt the canary traffic shifting and analysis until the confirm webhook returns HTTP status 200.
Flagger also comes with load testing that can generate traffic during analysis. You can read more about Webhooks - Flagger.
Let’s look at developer experience for both tools.
Developer Experience
Flux and Flagger both have a high learning curve and a lot of functionality, which means more power and can sometimes overwhelm the developer. Both don’t have any UI. The setup experience is pretty straightforward. If you talk about logging experience, you might need to get your hands dirty in CLI; otherwise, in other tools, you might have a UI that will show you the current progress of deployment. This makes life easier for a lot of developers.
Conclusion
We look at both tools and how they fit in our CI/CD pipeline and help us deliver progressively. With the use of Flagger, we can split traffic into proportions, which helps in testing out new releases to a subset of users or even getting feedback. Whether a new release should be released or not to all users.
I hope you learned how these tools fit into GitOps with Progressive Delivery practice.
If you are looking to switch to Progressive Delivery with GitOps, talk to our CI/CD experts, who can help you not only suggest but also implement such a solution end to end.
References and further reading:
- Stefan Prodan on Flux, Flagger and the Operator pattern
- GlooOps: Progressive delivery, the GitOps way
- GitOps
- Guide to GitOps
- InfraCloud’s Progressive Delivery Consulting services
- GitOps consulting and implementation capabilities
Looking for Progressive Delivery consulting and support? Explore how we’re helping companies adopt progressive delivery - from creating a roadmap to successful implementation, & enterprise support.
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like







{kind=link}