Oracle Database Backup and Recovery on Kubernetes using K10
 Ajay Kangare
Ajay Kangare  Anjul Sahu
Anjul Sahu Do you run Oracle database in containers? Do you run it on Kubernetes? Are you worried about data management – Backup & Recovery? To answer these questions, please read this article. In this post, we explore backup and recovery mechanism of a Oracle database deployed on Kuberentes. using the Kasten K10 data management platform. The backup and recovery strategy is to protect the database against data loss and reconstruct the database after data loss. Oracle database has multiple ways to create and manage the backup and restore, here we will talk about the application consistent backup and restore using third party snapshot technology like AWS EBS Snapshot.
In Application consistent backup, the Application is notified that the backup is being taken and application transactions/writes are quiesced for a short duration. Application consistent snapshots require quiescing the application to get consistent snapshots. Quiescing the application in contexts of cloud-native applications such as Oracle would mean flushing the in-memory data to disk and then take a snapshot.
In the case of Oracle database, a consistent backup would be done when:
- The current redo is archived, triggering a checkpoint that would write dirty buffer into the files.
- The database is put in hot backup mode prior to 12c. If you are using 12c or later, we can use storage snapshot optimization feature. This will freeze the I/O to datafiles while the snapshot is taken.
- A third-party snapshot is taken.
- End of backup mode, not required for 12c and later.
- Switch of the log file and optionally, backup of Control file to a backup file.
Our solution is based on the below support notes available on Oracle support [you would need a login to access them, see references].
Note: Block Corruption (particularly lost write) can not be fixed by Snapshot based recovery. It requires RMAN or Dataguard for full protection.
About Kasten K10 Platform

Kasten K10 Ecosystem Source: Kasten Documentation
The Kasten K10 data management platform, purpose-built for Kubernetes, provides enterprise operations teams an easy-to-use, scalable, and secure system for backup/restore, disaster recovery, and mobility of Kubernetes applications.Kasten K10 comes with an excellent dashboard to manage the applications in the cluster, and you can create a policy to take a snapshot and restore it. K10 have multiple components, lets understand a few of them which we will require to achieve our goal.
- Location Profile: In real backups, need to enable cross-cluster and cross-cloud application migration to store the snapshot data in case of cluster failure so the K10 profile needs to be configured with access to external object storage.
- Policies: Policies allow defining the actions that need to be taken when the policy is executed. The action could be to perform a snapshot or to perform an import of a previously exported backup. The frequency at which the action should be performed, the retention period, the selection of resources to backup are all defined in the policy. The policy also refers to a Location profile.
You can read more about Kasten K10 here.
Let’s get started with backup and recovering Oracle DB on K8s
We will create an Oracle database deployment on the Kubernetes cluster with persistent storage and then perform the backup and restore using Kasten.
Installing the Oracle database in a container
To install the Oracle database using deployment file with different available 12c, 18c and 19c please refer to Github repo’s oracle12c, oracle18ee, and oracle19ee directory respectively. If your Oracle database is not in the container, then please follow this Github repo by Oracle to run the database in a docker container.
Integrating Oracle Database with Kasten K10
Make sure the Kasten K10 application is installed in your cluster, if not please install it, refer to Kasten documentation
Once you access the K10 dashboard, create a K10 profile.
- Go to Setting > Location > Create Location Profile
- Provide details required, validate, and save.
 ](https://github.com/infracloudio/Kasten-K10-Oracle-Blueprint/blob/master/Images/location_profile.png)
](https://github.com/infracloudio/Kasten-K10-Oracle-Blueprint/blob/master/Images/location_profile.png)
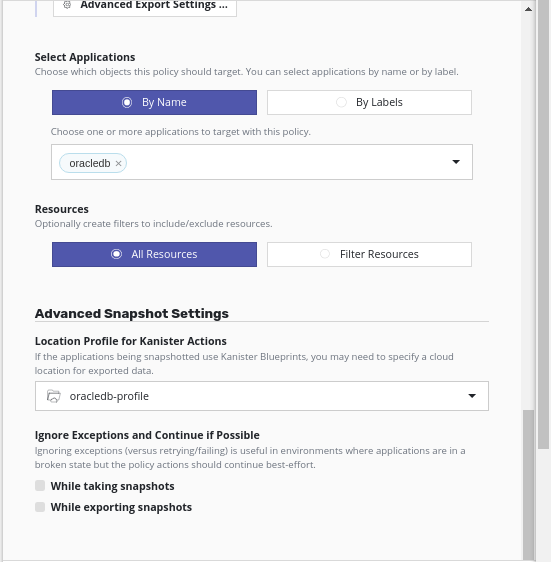
Now create a K10 policy for your application.
- Go to Policies
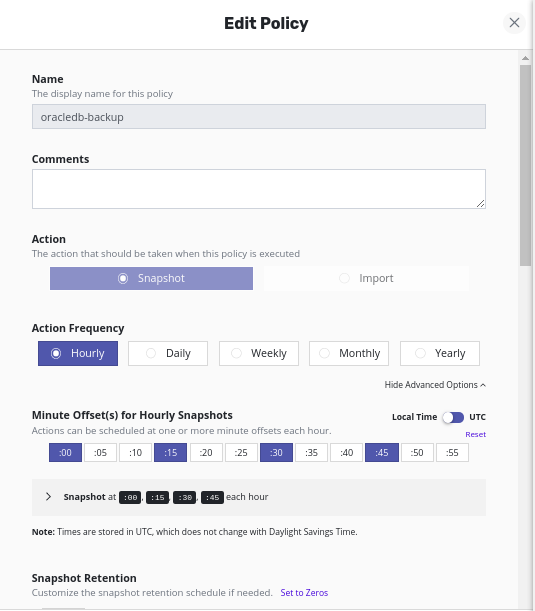
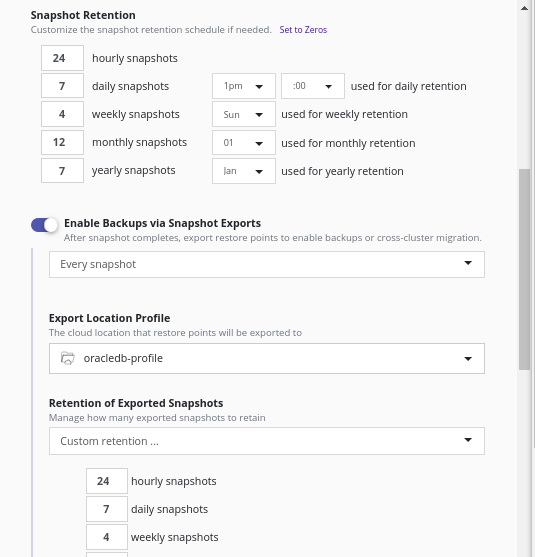
- Create a policy and give some name
- Select action type as a snapshot
- Provide Action frequency
- Select the available application
- Select Location Profile for Kanister Actions
- Create Policy
Install Blueprint
The platform allows domain experts to capture application specific data management tasks in blueprints which can be easily shared and extended. The framework takes care of the tedious details around execution on Kubernetes and presents a homogeneous operational experience across applications at scale. Further, it gives you a natural mechanism to extend the K10 platform by adding your own code to modify any desired step performed for data lifecycle management.
To create Blueprint in the same namespace as the Kasten controller. This blueprint is having 3 actions which are performed while backup and restore.
backupPrehook: This action will be executed before the actual snapshot backup, create a restore.sql script with recovery time and SQL statement to recover from the database first in host persistence location, and then archive the current logs.backupPosthook: This action will be executed after the snapshot backup is done and archive the current logs.restore: After restoring from the k10 dashboard and once the pod is in the ready state this action will be executed and run the restore.sql script to make sure that recovery is done properly.
$ kubectl create -f blueprint.yaml -n kasten-io
Annotate the Oracle Database deployment with a newly created blueprint.
$ kubectl -n {NAMESPACE} annotate deployment.apps/{DEPLOYMENT_NAME} kanister.kasten.io/blueprint={BLUEPRINT_NAME}
Create a schema and run the load
Once the Oracle database is running, you can populate it with some data. Let’s create a schema and generate some load. To generate data in the Oracle database for simulating load, we are using Swingbench. Swingbench is equipped with a utility like oewizard which loads data. You can use SwingBench GUI from outside the pod to run the load but may lead to an increase in latency. My suggestion is to copy swingbench in the Oracle container/Pod and use CLI options as shown below.
$ cd /opt/oracle/oradata/swingbench/bin/
$ ./oewizard

OR
You can copy the Swingbench to your running pod and run from there for faster operation.
# Download and copy SwingBench zip file to pod persistant volume.
$ kubectl -n NAMESPACE cp swingbenchlatest.zip {POD_NAME}:/opt/oracle/oradata/
$ kubectl -n oracle19ee exec -it pod/{POD_NAME} -- bash
# Set Java path
$ export PATH=$ORACLE_HOME/jdk/bin:$PATH
# Unzip the downloaded file
$ cd /opt/oracle/oradata/
$ unzip swingbenchlatest.zip
$ cd swingbench/bin/
# Create a schema using oewizard
$ ./oewizard -scale 1 -dbap {DB_PASSWD} -u {username} -p {password} -cl -cs //{ORACLE_DB_CONNECTION_STRING} -df '/opt/oracle/oradata/ORCL/{PDB_NAME}/{TABLESPACE_NAME}.dbf' -create
$ ./oewizard -scale 1 -dbap "Kube#2020" -u soe -p soe -cl -cs //localhost:1521/ORCL -df '/opt/oracle/oradata/ORCL/ORCLPDB1/soe.dbf' -create
[](https://github.com/infracloudio/Kasten-K10-Oracle-Blueprint/blob/master/Images/oewizard_output.png)
Now start the load from the pod itself.
```shell
# concurrent number of users
$ USERS=30
# for five minutes
$ RUNTIME="00:05:00"
$ ./charbench -c ../configs/SOE_Server_Side_V2.xml -cs //localhost:1521/ORCL -dt thin -u soe -p soe -uc $USERS -v users,tps,tpm,dml,errs,resp -mr -min 0 -max 100 -ld 1000 -rt $RUNTIME
# Note you can change the values as per your requirement.
You can also use the Swingbench GUI app to generate load from outside the pod as well. Do note that there will more latency so it is going to take a bit more time. You can refer to the Swingbench guide to understand how it works.
$ cd /opt/oracle/oradata/swingbench/bin/
$ ./swingbench

Protect and backup the application using K10
You can now take a backup of the Oracle data using K10 policies for this application. Go to the K10 dashboard and run the policy. Please note down the timestamp while running the policy to make sure the DB will be restored at the same point. This will start the backup process and you can check the logs of currently running pod to see the pre backup and post backup actions are performed.
# To check the deployment pod logs
$ kubectl -n {NAMESPACE} logs {POD} -f
Confirm the backup action policy ran completely in the K10 dashboard.
How does Kasten backup work under the hood?
Under the hoods, depending on the Cloud platform’s volume snapshot technology. The backup will trigger a snapshot of volume along with all the configuration required to run the workload. As this is native to Kubernetes, it will backup objects like ConfigMap, Deployment, Persistent Volume, etc.
In our example, we have used AWS where the EBS snapshot happens immediately (point in time) and then it asynchronously is written to the S3 (in our case). The snap is immediate and doesn’t matter how big is your volume. But depending on the changes between the current snapshot and previous snapshot, the asynchronous write will take variable timing. And you can restore the full copy from any snapshot without about if you have copies of previous snapshots.
Simulating disaster or data loss
Let’s say one fine day, someone drops the Order table or corrupt it which is not an uncommon scenario. You can simulate data loss by dropping a table or modifying its content.
DROP TABLE SOE.ORDERS;
Restoring the K8s application using Kasten K10

To restore the missing data, you should use the snapshot that you created before. Let’s say someone accidentally deleted some data and want to restore data to the last backup point. In Kasten, you will get options to restore a subset of application, you can also restore a copy in different Kubernetes namespace or also if the snapshot is stored in the object store (location profile) in the cloud, you can take it to next level and restore in different cluster altogether.
Go to the K10 dashboard, select application restore point from which you want to restore, and confirm restore. This will start the restore process and create a new pod with the restore point snapshot.
Confirm the restore is done completely.
# Check If Pod is in ready state.
$ kubectl -n {NAMESPACE} get pods
# Once Pod is ready, connect to the DB and verify the table ORDERS last record and it should equivalent to start time.
$ kubectl -n {NAMESPACE} exec -it <POD> -- bash
sqlplus soe/soe@ORCLPDB
select SYS_EXTRACT_UTC(max(order_date)) from soe.orders;
exit;
Troubleshooting
If you run into any issues with the above commands, you can check the logs of the controller using:
$ kubectl --namespace kasten-io logs <KANISTER_SERVICE_POD_NAME>
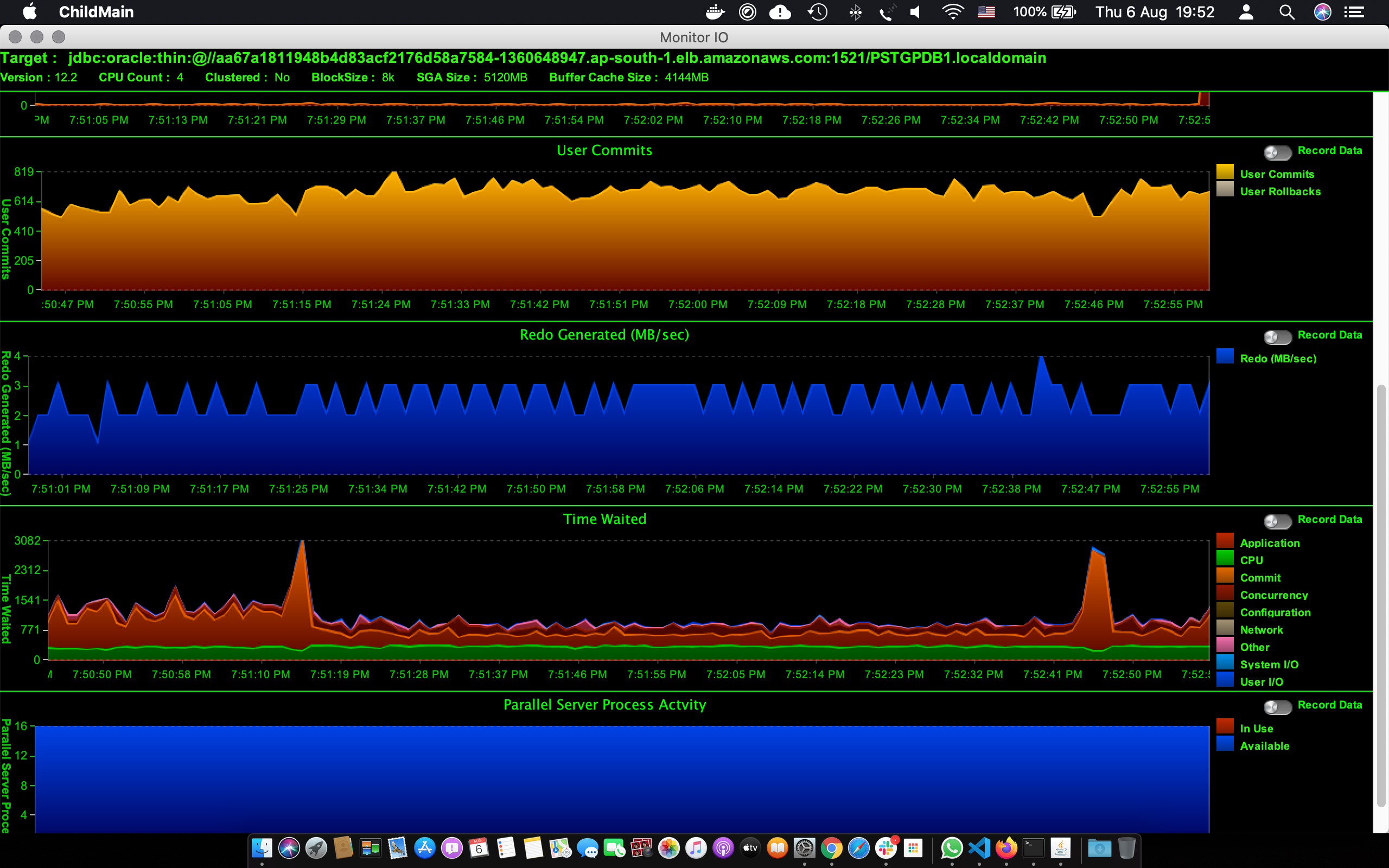
Performance of Oracle database during backup
While we were running synthetic load through Swingbench, we also took a series of AWR snapshots to analyze the performance penalty on the system. What we see is that with Oracle’s third party snapshot storage optimization (i.e. when you don’t need to put the database in backup mode), the impact is nearly 5 times lesser as compared to hot backup mode. Our recommendation is to test this with your setup as mileage will vary for each application and workload.
$ kubectl -n {NAMESPACE} exec -it {POD_NAME} -- bash
# to generate AWR report
$ sqlplus / as sqlplus
$ @?/rdbms/admin/awrrpt.sql
# provide the details like type, begin and end snapshot id, file name, it will create a AWR report, copy this file to local and analyze the report fot performace impact.
| # | Database Version | CPU / SGA | Users | Avg TPS | Total Tx / 5 min | Snapshot Size | Snapshot Time | Notes |
|---|---|---|---|---|---|---|---|---|
| 1 | 12.2.0.1 | 4C / 5G | 30 | 1000 | 300031 | 40G | 00:02:33 | |
| 2 | 12.2.0.1 | 4C / 5G | 200 | 1075 | 322516 | 40G | 00:04:30 |
Below is the database performance charts showing the number of commits, database time, and redo generated during the test. As you can see in the below chart, we ran a test at 7:52, Database time has a spike but there is not much impact on the number of transactions processed by the database. The end-user response time was intact. The spike is mainly due to increased time took the log file parallel write event for the short duration when the snapshot was taken.
Cleanup
Uninstalling the Deployment
To uninstall/delete the oracle deployment:
$ kubectl delete ns {NAMESPACE}
Delete BluePrint
Remove Oracle blueprint from the Kasten namespace.
$ kubectl delete blueprints oracle-blueprint -n kasten-io
Conclusion
As we move to a cloud native platform from the monolith enterprise architectures, the very popular database like Oracle is often the bottleneck or show stopper. You might already have an application modernization roadmap and you want to go fully cloud native, but sometimes, it might be hard for your organization to rewrite the application that uses Oracle due to complex customization, heavy database-centric design, or you might be using applications that need Oracle database as a prerequisite. In many cases, you can containerize the Oracle database and orchestrate using Kubernetes. It improves availability and reduces the operational cost of managing the databases and works in the same way how other cloud native systems work in your enterprise. When you decide to move on, the next important step is the need for data management i.e. backup and recovery, disaster recovery, and application mobility where the Kasten K10 platform can help. In this post, we have suggested a solution to how we can use K10’s extensible framework for providing a data management layer for the Oracle database.
If you need more information, please feel free to contact us directly or through Twitter.
Below screencast is the summary of what we have showcased above.
References
- Improving Oracle backup and recovery performance with Amazon EBS multi-volume crash-consistent snapshots
- Github Repo of the code we have used in this solution
- Kasten Documentation
- Oracle Documentation for 12c and 19c
- Oracle docker images for 12c and 19c
- Dominic Giles’s Swingbench Documentation
- Kubernetes Disaster Recovery using Kasten’s K10 Platform
- Preventing, Detecting, and Repairing Block Corruption: Oracle Database 11g
- How to prepare the Oracle database for Snapshot Technologies and ensure a consistent recovery 221779.1
- Supported Backup, Restore and Recovery Operations using Third-Party Snapshot Technologies(604683.1)
This solution is jointly written by Infranauts – Ajay Kangare and Anjul Sahu
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like