
Tuning EMQX to Scale to One Million Concurrent Connection on Kubernetes
 Tushar Purohit
Tushar Purohit  Burhan Shaikh
Burhan Shaikh When building an IoT-based service, we need to implement a messaging mechanism that transmits data collected by the IoT devices to a hub or a server. That mechanism is known as a messaging protocol. A messaging protocol is a set of rules and formats that are agreed upon among entities that want to communicate with each other.
When dealing with IoT, one of the first things that come to mind is the limited processing, networking, and storage capabilities these devices operate with. These constraints make it challenging to implement a messaging protocol to facilitate communication. Ideally, we should use a protocol that takes all these issues into consideration.
Enter MQTT. A messaging protocol that is lightweight, efficient, and reliable, designed specifically for the low-power and low-bandwidth environments of IoT devices. It has become the go-to choice for developers building services on top of devices that require fast, real-time communication and efficient use of limited resources.
As the clients grow, scaling becomes a concern even for a service running on a protocol as efficient as MQTT. To ensure clients can enjoy seamless connectivity, it’s essential to optimize the infrastructure, components, and processes of the MQTT Broker itself.
There are multiple brokers available like VerneMQ, HiveMQ, Mosquitto. For this blog post, we will be using the open source version of EMQX as our MQTT Broker of choice, as it is widely used in the industry thanks to its high scalability, reliability, and performance.
In this post, we’ll dive deeper into how we could run EMQX on Kubernetes on a scale of up to 1 million connections and the challenges associated with it.
What is MQTT?
Messaging is a mechanism that allows systems to exchange information asynchronously and reliably without being tightly coupled to one another.
Some of the widely used protocols are
- WebSocket - powers live chats.
- WebRTC - enables real-time communication between browsers and devices.
- XMPP - allows for cross-platform communication.
There is another protocol that has been designed for Machine to Machine communication, especially for IoT devices that operate with resource and network constraints and that is MQTT.
MQTT uses a Pub/Sub model and offers following benefits:
- Small code footprint
- Compressible binary format for message payloads
- Reduced device active time for sending and receiving messages
- Quality of Service (QoS) levels
Why run MQTT on Kubernetes?
Running MQTT on Kubernetes offers a wide range of benefits such as:
-
Single point of contact: Clients have a single endpoint to connect to and the load gets distributed across the broker pods.
-
Fault tolerance: Even if some of the broker pods/nodes go down, there are others available to keep your service running reliably. The client does not need to take any corrective action, they will automatically get connected to another broker.
-
Intelligent scaling: Add and remove brokers on the fly based on events and/or traffic/resource utilization. This helps you to cater to demand and optimize your spending.
-
Self healing and efficient administration: A broker usually serves hundreds of IoT devices and at such a scale, a self-healing platform like Kubernetes reduces the overhead of repetitive manual administration and improves efficiency.
What is EMQX?
EMQX is one of the most widely used MQTT Platforms in the industry. It has the capability to support millions of connections and offers sub-millisecond latency.
It offers distributed MQTT brokers that enable us to use it natively on Kubernetes. It is essential for the broker to be distributed to be deployed on Kubernetes because a client’s connection could end up on any of the broker pods and messages would need to be forwarded among them so that they are properly delivered to the relevant subscribers.
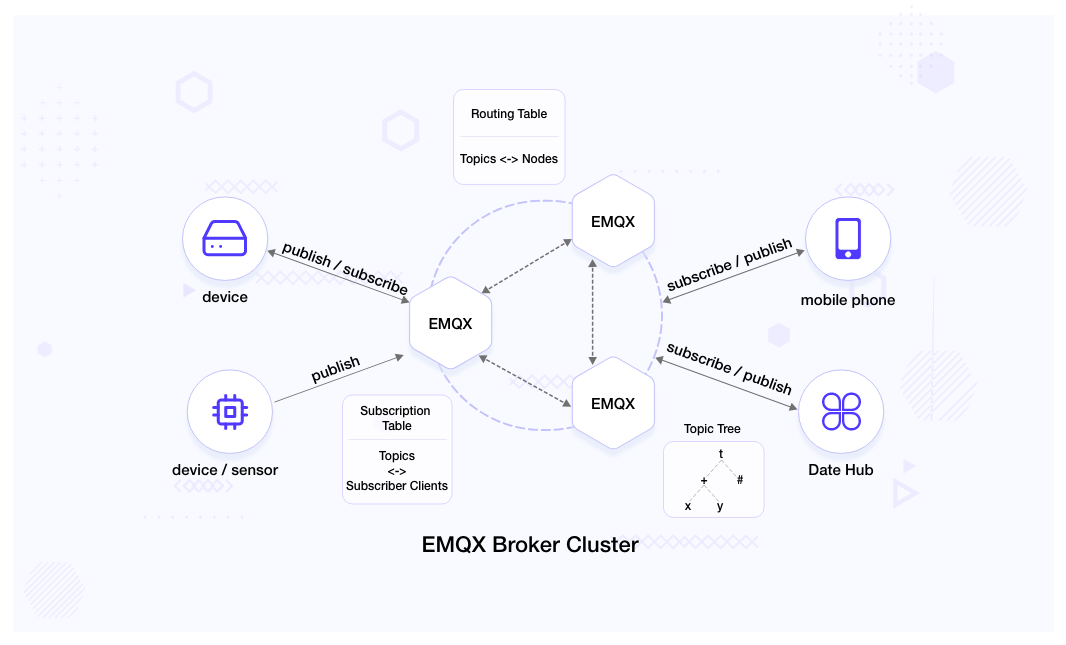
EMQX broker cluster maintains two tables and a tree:
- Subscription table: Topics are mapped to the subscribers and the table exists only on the broker node to which the subscriber is connected.
- Routing table: Topics are mapped to the node to which the subscriber is connected to. Every broker node maintains a copy of this table.
- Topic tree: Every broker node maintains a topic tree representing the relation among the topics, subscribers and broker nodes.
Running EMQX on Kubernetes
The first step is to spin up a Kubernetes Cluster. To ensure optimal performance, it is essential to select the right machine size for our cluster’s worker nodes onto which the broker pods will be deployed.
The decision to select the right machine size comes down to several factors:
- Number of clients connected to the broker.
- Message throughput - Number of published and subscribed messages processed by the broker per second.
- Quality of service - Higher the QoS, the more resources are consumed.
- Size of the payload - The larger the size of the payload to be sent over MQTT the more resource is the utilization.
- Number of topics - As more topics get added to the route table resource, utilization also increases. Distributed EMQX uses Route Tables to route messages to the right nodes in order to deliver messages to the subscriber.
One of the simplest ways out is to use EMQX Server Estimate calculator. This calculator has been developed and tested according to the above-mentioned parameters. You will need to feed the number of clients (expected) that will connect to the broker and the throughput (number of messages sent and received) in a second.
Let’s consider that for our use case, we need 16 CPU Cores and 32 GB of Memory. Instead of running a single node of this size, we could divide it among multiple nodes and then deploy multiple EMQX broker pods on it. This would introduce fault tolerance and we can scale in and scale out both pods and nodes depending on the usage.
- You can use the Learnk8s Kubernetes Instance Calculator to see which instance type will offer you better efficiency by feeding the broker pod resource requests to the calculator.
- You will however need to test this out by performing load tests to see how well the broker performs under stress.
To Install the EMQX Broker on Kubernetes we can use its Helm Chart.
We are using Amazon EKS. You could use any other Kubernetes cluster as long as it allows you to modify sysctl parameters or to run a user data script of sysctl commands on the nodes and also allows you to add kubelet parameters to the cluster bootstrap script in order to whitelist them. Most of the major cloud providers allow such configuration in some way or the other. We have specified a couple of examples later in this blog post.
Tuning for 1 Million Concurrent Connections
When we want our EMQX system to support 1 million concurrent connections, we will need to tune different system components to make this happen. Using out-of-the-box configuration might not help us reach this scale.
Here are the following components that need calibration:
- Linux Kernel
- Erlang VM
- The Broker
Linux Kernel Tuning
Tuning the kernel level parameters is not very straightforward to do so on a managed Kubernetes service especially when sysctl commands are not supported out of the box - as it should be for security reasons.
EMQX recommend’s to calibrate these parameters. They can improve the performance of any broker and not just EMQX.
We will be going through how to configure them but first let’s define them.
-
Sockets IPC API used in Linux TCP/IP connections uses file descriptors. Therefore, the number of opened file descriptors is one of the first limits we may face.
# Sets the maximum number of file handles allowed by the kernel sysctl -w fs.file-max=2097152 # Sets the maximum number of open file descriptors that a process can have sysctl -w fs.nr_open=2097152 -
MQTT runs on TCP so we will need to modify several of its parameters as well.
# Sets the maximum number of connections that can be queued for acceptance by the kernel. sysctl -w net.core.somaxconn=32768 # Sets the maximum number of SYN requests that can be queued by the kernel sysctl -w net.ipv4.tcp_max_syn_backlog=16384 # Setting the minimum, default and maximum size of TCP Buffer sysctl -w net.ipv4.tcp_rmem='1024 4096 16777216' sysctl -w net.ipv4.tcp_wmem='1024 4096 16777216' # Setting Parameters for TCP Connection Tracking sysctl -w net.netfilter.nf_conntrack_tcp_timeout_time_wait=30 # Controls the maximum number of entries in the TCP time-wait bucket table sysctl -w net.ipv4.tcp_max_tw_buckets=1048576 # Controls Timeout for FIN-WAIT-2 Sockets: sysctl -w net.ipv4.tcp_fin_timeout=15
Now that we have specified the kernel parameters that need calibration, we need an approach to implement this when running our broker on Kubernetes.
In the container world sysctls are classified into two types:
-
Non-Namespaced:
-
The ones that should be set on node/global level and the same values are used across all processes running on the node, be it containerized or non-containerized. They cannot be set on a container/pod level.
-
Some of them can still be set via a container on the node level but it will require elevated privileges and the setting can impact the entire node. This is not recommended from a stability and security point of view.
-
-
Namespaced: The ones that can be independently set on a container level
Kubernetes further categorizes sysctl calls into two:
- Safe: sysctl calls that are unlikely to cause any system instability or security issues when modified and do not influence other pods running on the node.
- Unsafe: sysctl calls that have the potential to cause system instability or security issues and can affect other workloads running on the machine. Some kernel parameters can even allow a container to consume excessive system resources leading to a denial of service.
You can read more about sysctls here.
Let’s list the sysctls that we can set on the node level, basically the non-namespaced sysctls:
sysctl -w fs.file-max=2097152
sysctl -w fs.nr_open=2097152
Here are the namespaced sysctls:
sysctl -w net.core.somaxconn=65536
sysctl -w net.ipv4.tcp_max_syn_backlog=16384
sysctl -w net.ipv4.tcp_rmem='1024 4096 16777216'
sysctl -w net.ipv4.tcp_wmem='1024 4096 16777216'
sysctl -w net.netfilter.nf_conntrack_tcp_timeout_time_wait=30
sysctl -w net.ipv4.tcp_max_tw_buckets=1048576
sysctl -w net.ipv4.tcp_fin_timeout=15
Every network namespace gets its parameter values from the init namespace. A container has its own network namespace. This is why setting the net.* sysctls on the node level will configure them on the root network namespace and not reflect inside of the container.
There are some more namespaced sysctls that will improve the performance but because of an active issue we are not able to set them on the container level:
# Sets the size of the backlog queue for the network device
sysctl -w net.core.netdev_max_backlog=16384
# Amount of memory that is allocated for storing incoming and outgoing data for a socket
sysctl -w net.core.rmem_default=262144
sysctl -w net.core.wmem_default=262144
# Setting the maximum amount of memory for the socket buffers
sysctl -w net.core.rmem_max=16777216
sysctl -w net.core.wmem_max=16777216
sysctl -w net.core.optmem_max=16777216
Setting the non-namespaced sysctls
We will run the sysctl commands at the time of node creation before it is registered as a worker node for the Kubernetes cluster. This way we can calibrate the kernel parameters consistently across the nodes at scale.
We will need to set the sysctl commands in the pre_bootstrap_user_data of self-managed Amazon EKS node groups via Terraform.
self_managed_node_groups = {
worker-a = {
name = "worker-a"
key_name = "worker-a"
min_size = 1
max_size = 4
desired_size = 2
create_launch_template = true
enable_bootstrap_user_data = true
pre_bootstrap_user_data = <<-EOT
sysctl -w fs.file-max=2097152
sysctl -w fs.nr_open=2097152
EOT
}
}
Azure Kubernetes Service (AKS) supports customizing the Linux kernel parameters via the Linux OS Custom Configuration. If using Terraform we need to specify these parameters under the linux_os_config.
Google Kubernetes Engine (GKE) allows the same via the Node System Config. If using Terraform we need to specify the parameters under node pool -> node_config -> linux_node_config.
Setting namespaced sysctls
Most of the sysctl commands that we want to use fall under the unsafe category and have been disabled by default by Kubernetes.
To enable unsafe sysctl calls on Kubernetes we need to whitelist them by adding them to the kubelet start script, and this is to be done per node group basis.
It is a good practice to restrict these changes only to specific nodes and schedule the workloads that need these parameters enabled onto them. In our case, we should only schedule EMQX pods on these nodes. This will help reduce the surface for an attack. Taints and Tolerations and Node Affinity will help us implement this practice.
We need to pass these kernel parameters with a flag --allowed-unsafe-sysctls to the kubelet. On Amazon EKS we need to pass them under the --kubelet-extra-args flag. Using Terraform we can specify these parameters in the self-managed node group’s bootstrap_extra_args.
node_group_2 = {
name = "venus"
min_size = 1
max_size = 5
desired_size = 2
bootstrap_extra_args = "--kubelet-extra-args '--allowed-unsafe-sysctls \"net.core.somaxconn,net.ipv4,
tcp_max_syn_backlog,net.ipv4.tcp_rmem,net.ipv4.tcp_wmem,net.netfilter.nf_conntrack_tcp_timeout_time_wait,
net.ipv4.tcp_max_tw_buckets,net.ipv4.tcp_fin_timeout\"'"
}
On AKS we can specify them using Linux Kubelet Custom Configuration. If you are using Terraform kubelet_config block has an attribute allowed_unsafe_sysctls.
Once these are whitelisted we will have to set them via the values.yaml file under podSecurityContext.
sysctls:
- name: net.core.somaxconn
value: "32768"
- name: net.ipv4.tcp_max_syn_backlog
value: "16384"
- name: net.ipv4.tcp_rmem
value: 1024 4096 16777216
- name: net.ipv4.tcp_wmem
value: 1024 4096 16777216
- name: net.ipv4.ip_local_port_range
value: ”1000 65535”
- name: net.ipv4.tcp_max_tw_buckets
value: "1048576"
- name: net.ipv4.tcp_fin_timeout
value: "15"
- name: net.netfilter.nf_conntrack_tcp_timeout_time_wait
value: "30"
Please note that only namespaced sysctls are configurable via the pod securityContext within Kubernetes.
If you are using a Kubernetes version that still uses Pod Security Policies, you will need to create a pod security policy and explicitly specify the unsafe sysctls for the pod to be able to run those sysctl commands.
If the Kubernetes version supports the Pod Security Admission and Pod Security Standards and the default settings are enforce: privileged then you do not need to do anything. Otherwise, you can configure the pod security standards on the namespace level.
Erlang VM Tuning
EMQX Broker is based on the Erlang/OTP platform that runs on Erlang VM (think on the lines of Java Virtual Machine (JVM). We have to optimize its parameters to ensure that the broker can handle a large number of concurrent connections and processes without running out of resources.
## Erlang Process Limit
node.process_limit = 2097152
## Sets the maximum number of simultaneously existing ports for this system
node.max_ports = 2097152
As we are running EMQX Brokers as pods, we have to configure the Erlang VM parameters on the container level. Given that we are deploying the brokers via Helm Chart we can set these parameters via the values.yaml file under emqxConfig.
emqxConfig:
# Other configuration…
# Erlang Process Limit
EMQX_NODE__PROCESS_LIMIT: 2097152
# Sets the maximum number of simultaneously existing ports for this system
EMQX_NODE__MAX_PORTS: 2097152
EMQX Broker Tuning
We need to configure the broker’s external TCP listener’s configuration to increase the number of TCP connections it can accept and also specify the number of acceptor threads that the listener should use to handle incoming connection requests.
# Other configuration…
EMQX_LISTENER__TCP__EXTERNAL: "0.0.0.0:1883"
EMQX_LISTENER__TCP__EXTERNAL__ACCEPTORS: 64
EMQX_LISTENER__TCP__EXTERNAL__MAX_CONNECTIONS: 1024000
These also need to be specified under the emqxConfig.
Testing the EMQX Broker’s Performance
Now that you have performed the tuning, it’s time to test the broker’s performance.
We will be using the emqtt-bench tool for testing. There are many MQTT benchmarking tools available such as mqtt-benchmark and others.
Testing a broker with 1 million concurrent connections is not a simple task. It is recommended to create multiple test machines, perform tuning of these client machines to support a large number of connections and then start sending out MQTT connections to the broker from these clients.
You can also run fewer stress-testing machines with better configuration and use multiple network cards to send out more connections from a single machine. For reference - device-and-deployment-topology
The tuning to be performed on every client machine:
sysctl -w net.ipv4.ip_local_port_range="500 65535"
echo 1000000 > /proc/sys/fs/nr_open
ulimit -n 100000
We want to have 1 million concurrent connections in total. Let’s start with 50 thousand connections from each stress testing machine or if you have configured your machine to use several network cards you can fire off 50k connections from each network card.
Refer the emqtt_bench conn command.
./emqtt_bench conn -c 50000 -h 216.105.138.192 -p 1883 -u myuser -P mypass
44s connect_succ total=28822 rate=659.00/sec
45s connect_succ total=29485 rate=663.00/sec
46s connect_succ total=30147 rate=662.00/sec
47s connect_succ total=30797 rate=650.00/sec
48s connect_succ total=31450 rate=653.00/sec
49s connect_succ total=32013 rate=562.44/sec
50s connect_succ total=32171 rate=158.16/sec
51s connect_succ total=32337 rate=164.36/sec
52s connect_succ total=32502 rate=165.33/sec
2m42s connect_succ total=49554 rate=143.71/sec
2m43s connect_succ total=49702 rate=147.70/sec
2m44s connect_succ total=49844 rate=142.28/sec
2m45s connect_succ total=49986 rate=143.29/sec
2m46s connect_succ total=50000 rate=14.00/sec
# If you have multiple network cards:
./emqtt_bench conn -h 216.105.138.192 -p 1883 -c 50000 --ifaddr 192.168.0.100
./emqtt_bench conn -h 216.105.138.192 -p 1883 -c 50000 --ifaddr 192.168.0.101
./emqtt_bench conn -h 216.105.138.192 -p 1883 -c 50000 --ifaddr 192.168.0.102
# So on and so forth……
We can monitor the current number of connections via the EMQX Dashboard by port forwarding the EMQX pod at http://localhost:18083/.
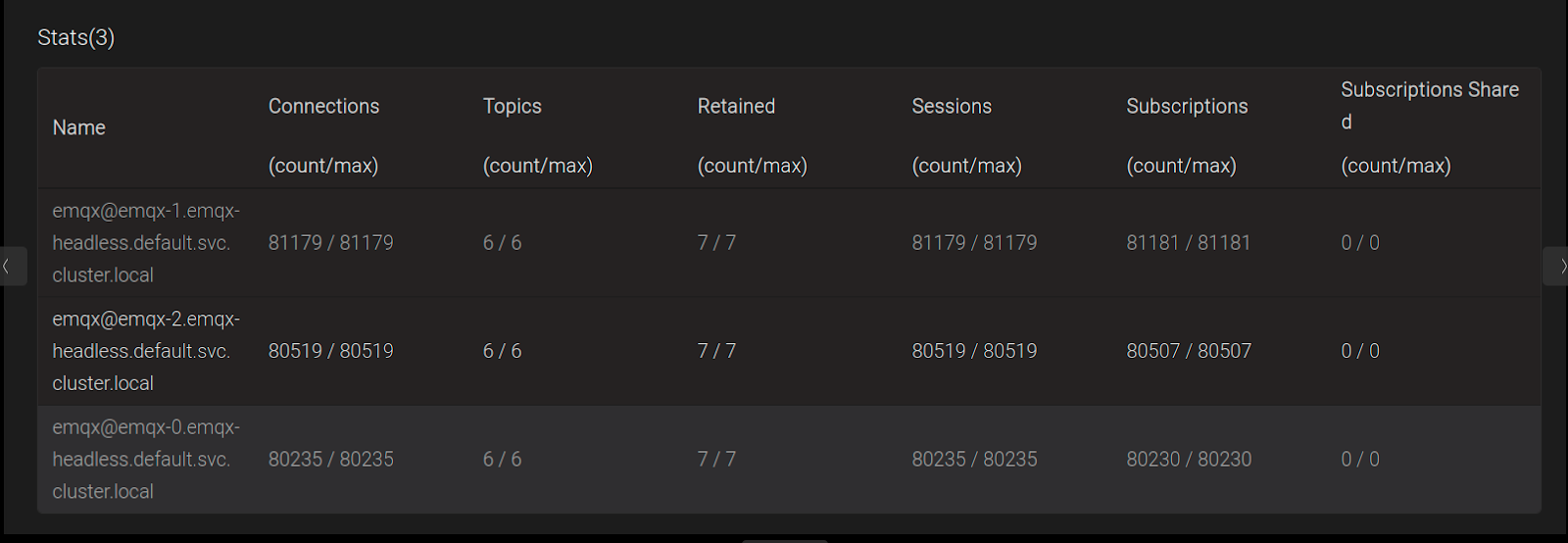
The “Connections count” shows the current active connections on each EMQX Broker Pod and it keeps on growing during the testing.
You can also run this command inside the emqx pod:
./bin/emqx_ctl listeners
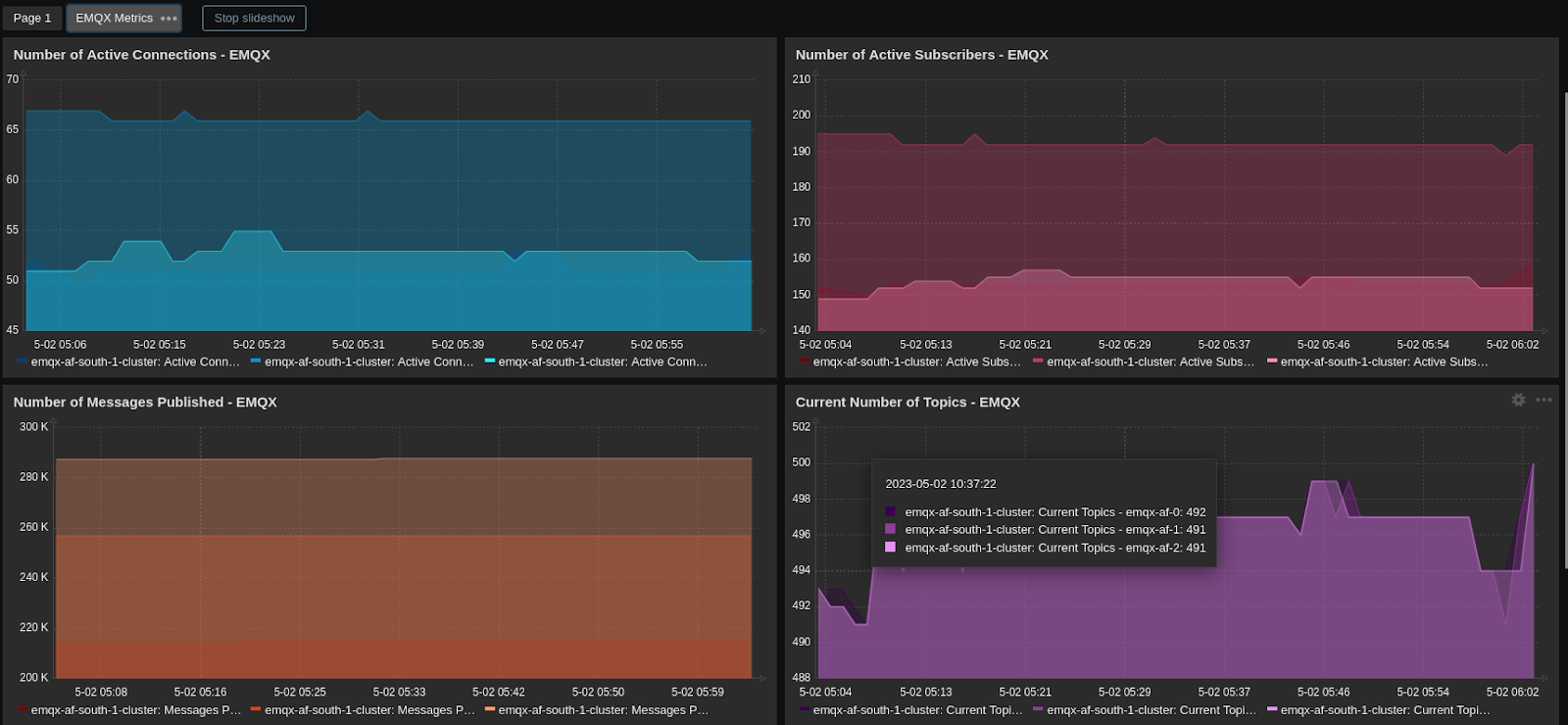
If you have Prometheus configured with push-gateway then you can use emqx prometheus plugin to push data to the push-gateway which is then pulled by the Prometheus server. This will also help you monitor the EMQX stats such as the number of active connections on your dashboards.
Conclusion
We talked about MQTT and the benefits of running it on Kubernetes. We used EMQX as the MQTT platform of choice and delved into the nitty-gritty of scaling it to handle up to 1 million concurrent connections. We also discussed how to configure test machines to simulate these high loads and benchmark the performance of the brokers.
By following the steps outlined in this post, you can ensure that your EMQX brokers are optimized to handle the demands of your MQTT-based applications and deliver the performance and reliability that your users expect.
We would like to hear your perspective on this. Please feel free to reach out to Tushar and Burhan to start a discussion and share your thoughts.
Looking for help with building your DevOps strategy or want to outsource DevOps to the experts? Learn why so many startups & enterprises consider us as one of the best DevOps consulting & services companies.
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like






