Everything Starts with the Service Catalog: A Practical Guide to Modeling Your IDP

Let’s be honest - most Internal Developer Platforms (IDPs) end up as dashboards with scattered data. They promise a lot: better developer experience, less cognitive overhead, smoother onboarding. But if you peek under the hood of many setups, they’re just collections of disconnected resources with no meaningful structure.
Why does this happen? Most platform teams start by integrating the existing tools like CI/CD pipelines, code repositories, registries, infrastructure automation, etc. They focus on integration first, thinking they can figure out the structure later. But without a proper mental model of what you want, you end up with a disconnected system.
Here’s the core problem: the data model is usually an afterthought.
If you want your platform to actually deliver on its promise, you need to start with a clear understanding of what you’re modelling. In this blog post, we’ll walk through an approach that puts the Service Catalog at the center of everything, because in most modern engineering orgs, that’s exactly how it works in practice.
Why Service Catalogs are the real foundation
Think about how work flows through your organization. Features, bugs, and incidents don’t get assigned to random teams or repos - they’re tied to services and *applications. These are the atomic units of the value chain - what you deploy, monitor, secure, and support.
And yet, we’ve seen plenty of IDPs built around “projects,” “environments,” or even “repos.” These models break down fast, especially as orgs scale. You end up with duplication, missed ownership, unclear dependencies, and a general sense of drift.
A service catalog gives you a solid and reliable anchor that reflects the reality of how your org thinks, ships, and operates. When you model around services, everything else - deployments, incidents, metrics, dependencies - naturally falls into place.
The Core Model: Five entities that matter
Here’s the model we’ve seen work with an enterprise client. It’s simple, but powerful.
1. Service (Application Component): The central object
Every core flow - deployments, SLOs, incidents, ownership, on-call, cost tracking — should start with a Service. This creates clear golden paths for developers to self-serve their infrastructure needs.
In practice, a “service” could be:
- A backend microservice like
payment-service - A frontend app like
dashboard-web - A shared library like
auth-lib - A stateful store like
user-db
Each of these maps belongs to a Component in your catalog (type: service, type: library, type: database, etc.).
Example: In Git, you might have:
git@company/payment-service.git→ Component:payment-service(type:service)git@company/auth-lib.git→ Component:auth-lib(type:library)git@company/user-db.git→ Component:user-db(type:database)
In Backstage, these would all be cataloged under kind: Component with different type values.
2. Team: Who owns it?
Every service should have a clear owning team. Teams are responsible for:
- Uptime and on-call
- Deployments
- Prioritization and roadmap
But ownership can sometimes be tricky - maybe a service was created by one team and is maintained by another. That’s why explicitly mapping teams to services is critical.
Example:
payment-service→ Owned bypayments-platform-teamauth-lib→ Owned bysecurity-engineeringuser-db→ Shared byuser-platformandinfra-data
This allows alerts, dashboards, and escalations to route correctly.
3. User: The individual contributor
While teams own services, individual users still matter for:
- Audit logs
- Pull request authorship
- Deployment permissions
- Escalations
Users should always be connected through teams, not directly to services, to maintain a clean ownership model that avoids fragmentation.
Example:
john@company.com→ Member ofpayments-platform-teamalice@company.com→ Member ofsecurity-engineering
So when auth-lib has a production issue, the incident escalation goes to security-engineering, not Alice directly.
4. Product: Grouping by business value
Products are customer-facing value bundles. A product typically spans multiple services and is how leadership thinks about capabilities.
Example:
- Product: “E-commerce Checkout”
cart-servicepayment-serviceinventory-service
- Product: “User Identity”
auth-libuser-dblogin-ui
This view helps with roadmap planning, measuring product-level uptime, and tying tech metrics to business outcomes.
5. Customer: The value recipient
A “customer” can be:
- An external end user (e.g., an online shopper)
- An internal team (e.g., a data platform team using your event pipeline)
Knowing which services impact which customers is essential for:
- Prioritizing incidents
- Coordinating rollouts
- Managing dependencies
Example:
inventory-service→ Impacts:E-commerce Customersevent-ingestion-service→ Impacts:Data Platform Teamauth-lib→ Impacts: All internal services requiring authentication
What ties this model together is a simple principle: everything revolves around the service. It’s the node that connects all the others, creating clear golden paths for developers to self-serve their infrastructure needs with minimal cognitive load, which is exactly how successful platform teams approach their Internal Developer Platform as a product.
Things people get wrong about IDP
There are a few common mistakes we’ve seen (and made) when modeling an IDP:
- Treating repos as services. Not everything in Git is a service. Some services span multiple repos. Some repos are just libraries, tooling, databases etc.
- Overcomplicating the user model. You probably don’t need to sync your entire HR database. Just enough to show who owns what, who’s active, and who’s on-call.
- Skipping customer mappings. Especially in B2B orgs, this is huge. Knowing which customers rely on which services helps prioritize incidents, rollouts, and feature flags.
- Ignoring service-to-service dependencies. This is essential for understanding blast radius and making informed changes. If your model has no graph, it’s flat and fragile.
- Allowing circular relationships between entities. These can quietly introduce chaos. For example, if Service is related to users, which is related to team, and team is related back to service, your tooling can end up in an infinite loop - or worse, give misleading dependency graphs. Always sanity-check for loops in your relationship model.
What makes a model scalable?
“Scalable” doesn’t only mean it can hold more data. It also means the model keeps working as your organization gets more complex.
That includes:
- New teams and services slot in easily, without manual glue.
- Relationships stay intact even as ownership shifts or teams reorganize.
- Clear discoverability - people can find the info they need without digging.
- Good enough performance and structure to support automations, scorecards, and workflows.
- Context-rich decisions - like pausing deploys during an incident, knowing who to page, or assessing production readiness.
If your IDP model needs rework every time your org evolves, it’s not scalable. A service-centric approach avoids that by creating a stable foundation supporting your platform’s product evolution.
Principles for a solid IDP data model
-
Start with a service-centric model
Everything should revolve around the Service - that’s the atomic unit of value in most engineering orgs. Services produce value, are owned by teams, consumed by customers, and backed by resources. -
Define clear, non-circular relationships
Avoid circular references likeTeam → User → Service → Team. This leads to brittle graph traversals and unpredictable outcomes. -
Keep relationships unidirectional when possible
For example:Service → Team(owns)
Service → Product(belongs to)
Service → Customer(serves)
Avoid relationships likeTeam ↔ Teamunless you have a solid use case (e.g., org chart). -
Avoid dumping everything into the Service blueprint
Services shouldn’t carry metadata that belongs elsewhere. For example, incident history belongs in anIncidentblueprint linked to aService, not embedded as property inside theService. -
Represent change over time cleanly
If something changes often (e.g.,Git SHA,build artifact,deployment), model it as a separate time-bound blueprint likeDeployment,Build, orCommit.
Example: A simple service-centric data model
Blueprints (core Entity types):
ServiceTeamUserCustomerProduct
Relationships:
Service→Team(ownership, runbook responsibility)Service→Product(which product it supports)Service→Customer(consumers of the service)Service→User(tech leads, on-call, reviewers)Team→User(members)Product→Customer(buyers/users)
This structure keeps services as the center, prevents circular references, and makes it easy to answer key questions like:
- “What does this team own?”
- “Who’s on call for this service?”
- “What services power this product?”
- “What customer touchpoints does this service impact?”
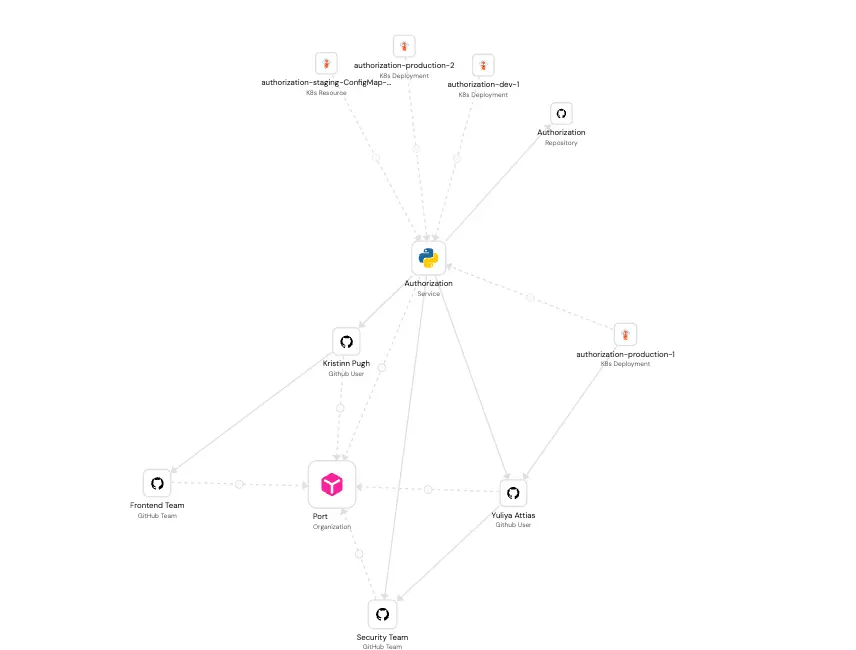
This diagram visually represents a service-centric data model, placing Service at the core and illustrating its relationships with Team, User, deployment, cluster, and organisation. It highlights how services act as the primary integration point between organisational units, technical ownership.
Making it real (using Port as an example)
There are a number of tools you can use to implement a service-centric IDP model - Backstage, Cortex, OpsLevel, Port, and even custom-built platforms using metadata stores or graph databases. The core principles we’ve laid out here apply across the board. If your platform models services well and captures their relationships clearly, you’re in a good place.
For the sake of clarity and practicality, I’ll use Port as the example here because it provides a flexible modeling framework with blueprints and relationships that map closely to the ideas discussed above. If you’re using another tool, the same logic still applies - you’ll just translate it into the concepts and structures that your platform supports.
In Port, you define these core Entity types as blueprints, which are schema definitions that model the structure and relationships of the entities in your internal developer platform - for example, Service, Team, User, Customer, and Product will be the blueprints. For example:
- User Blueprint (schema) with properties like id, name, email
- John Entity (row) with values: id=1, name=John, email=john.smith@improving.com
Start by defining your service blueprint. This should include properties like below, but not limited to:
- Name, description, type
- Linked repositories
- Deployment environments
- Owning team
- Runtime metadata (replicas, health etc.)
- SLOs, runbooks, dashboards
Below is a definition of a service catalog and its relations.
{
"identifier": "service",
"title": "Service",
"icon": "Microservice",
"schema": {
"properties": {
"description": {
"title": "Description",
"type": "string"
},
"type": {
"title": "Type",
"type": "string",
"enum": ["Backend", "Frontend", "Library"]
},
"tier": {
"title": "Tier",
"type": "string",
"enum": ["Mission Critical", "Customer Facing", "Internal Service"]
},
"runbooks": {
"title": "Runbooks",
"type": "array",
"items": {
"type": "string",
"format": "url"
}
},
"monitor_dashboards": {
"title": "Dashboards",
"type": "array",
"items": {
"type": "string",
"format": "url"
}
},
"healthStatusinProd": {
"title": "Health Status",
"type": "string",
"enum": ["Healthy", "Degraded", "Progressing"]
}
}
},
"relations": {
"repository": {
"title": "Repository",
"target": "githubRepository",
"many": false
},
"pager_duty_service": {
"title": "On-call (PagerDuty)",
"target": "pagerdutyService",
"many": false
},
"code_owners": {
"title": "Code Owners",
"target": "github_user",
"many": true
},
"dependencies": {
"title": "Depends On",
"target": "service",
"many": true
}
}
}
The above minimal service blueprint defines the core attributes of a software service in Port, including its type, tier, health status, runbooks, and dashboards. It also maps key relationships such as linked repositories, on-call ownership via PagerDuty, code owners, and service dependencies, making it ideal for visibility, incident response, and internal developer platform use cases.
Entity inside the Service blueprint
{
"identifier": "application",
"title": "application component",
"blueprint": "service",
"properties": {
"description": "Handles user authentication and profile management.",
"type": "Backend",
"tier": "Mission Critical",
"lifecycle": "Production",
"language": "Python",
"runbooks": ["https://docs.company.com/runbooks/user-service"],
"monitor_dashboards": ["https://grafana.company.com/d/user-service"],
"syncStatusinProd": "Synced",
"healthStatusinProd": "Healthy",
"syncStatusinTest": "Synced",
"healthStatusinTest": "Healthy",
"last_push": "2025-06-01T10:12:00Z",
"locked_in_prod": false,
"locked_in_test": false
},
"relations": {
"repository": "user-service-repo",
"pager_duty_service": "pd-user-service",
"code_owners": ["alice@company.com", "bob@company.com"],
"dependencies": ["auth-service", "notification-service"],
"domain": "identity"
}
}
This JSON defines an application entity in Port using the existing service blueprint. It captures essential metadata like service type, tier, lifecycle, deployment health, code ownership, dependencies, runbooks, and dashboards. This enables centralized visibility, on-call readiness, and integration with tools like GitHub and PagerDuty.
Once your services are modeled properly, you can plug in other entities:
- Teams sourced from GitHub, Okta, or even Terraform.
- Users pulled from SSO or Git history, or can be managed manually, directly into Port with Terraform.
- Products mapped manually or from product management tooling.
- Customers are linked manually in Port, or deployment pipelines, or from support systems.
More importantly, Port allows you to define relationships between these entities. That’s where things get powerful - when you can answer questions like:
- Who owns this service, and who’s on-call?
- What services support this product?
- If this service is degraded, which customers are impacted?
- What services are downstream of this one?
These aren’t abstract questions. They’re the ones your engineering and support teams ask every single day. If your IDP can’t answer them, it’s not doing its job.
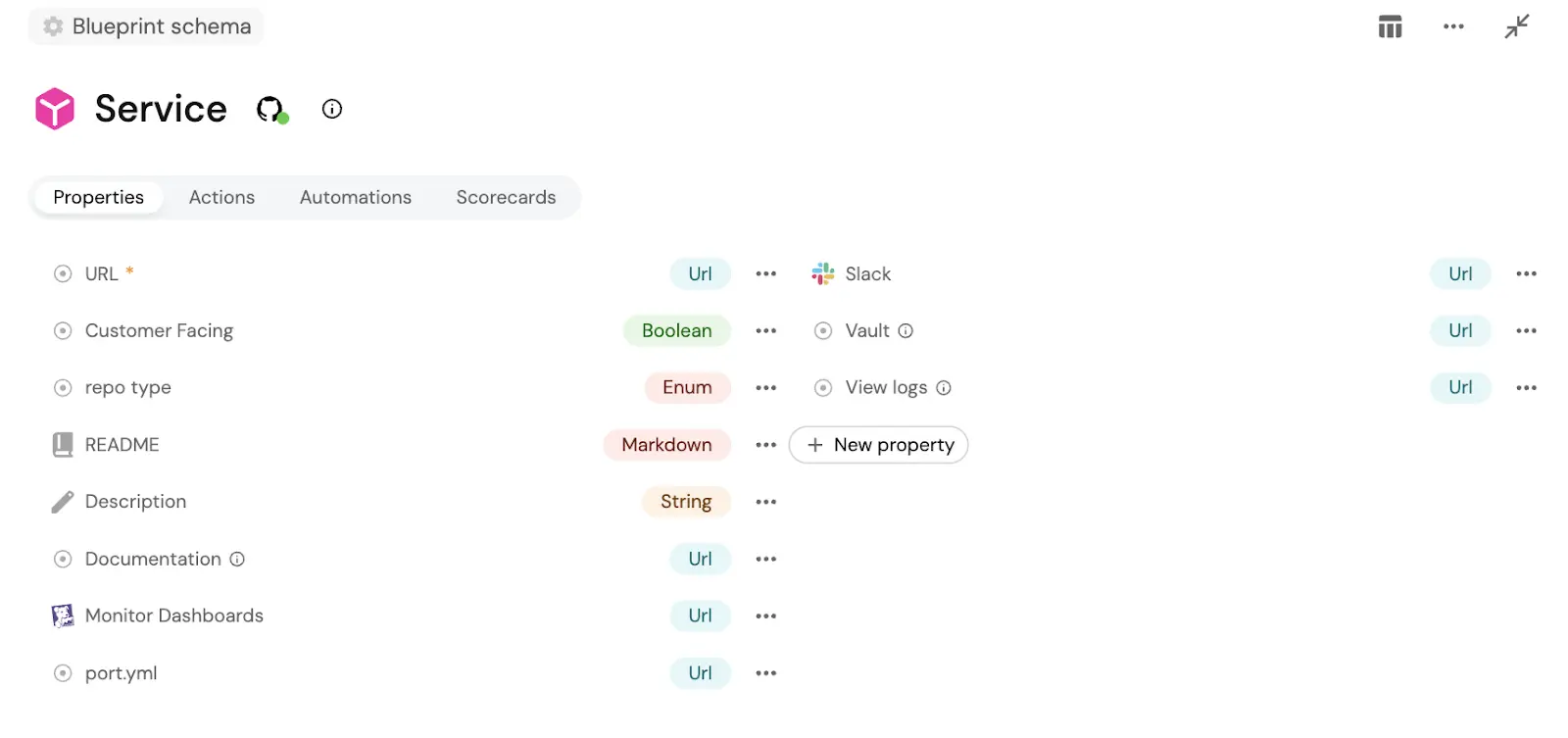
Example of a service blueprint definition below
Final thoughts
If you remember one thing from this post, let it be this:
Put service catalogs at the center. Build around reality, not abstraction.
A good IDP is like a well-designed map. It shouldn’t cover everything - just the things you need to navigate confidently. In most engineering orgs, that means knowing what services exist, who owns them, how they relate, and what value they deliver.
Model that well, and your platform becomes more than a dashboard. It becomes the connective tissue of your engineering organization. All of this will help your platform excel in this dynamic environment. If you’re looking for any help with building a platform the right way, you can also reach out to InfraCloud’s platform engineering experts, and let’s explore how InfraCloud can create a platform that truly serves your goals.
Exploring Platform Engineering? Read the other blog posts from our Platform Engineering series and browse webinars on our YouTube channel. Do share your thoughts on this article and platform engineering in general by connecting with me on LinkedIn.
Building a Platform? Download our free 22-page Platform Engineering OSS Reference Architecture eBook, which includes blueprints, frameworks, tool suggestions, maturity questionnaire, and much more!
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like








