Autoscaling Kubernetes Clusters on AWS EKS

Quick Summary:
We helped the customer to implement autoscaling of workload as well as the kubernetes infrastructure/nodes to offer scalability based on demand and use resources in most efficient manner to save overall cost.
Client Details
The customer is a venture-backed product company that helps government agencies in the US to operate and scale all government operations effectively by using state of the art software. They help many governments streamline operations such as ERP, Budgeting, financial management & citizen services, all via cloud-hosted software. They power more than 1000 governments.
Context and Challenges
The customer was using AWS & Kubernetes as an infrastructure platform and Datadog SaaS as the primary monitoring platform. They wanted to implement auto-scaling of workload and infrastructure/nodes to scale up and down based on demand and use resources in an optimal manner. The challenge was that Datadog at that point did not have direct integration with Kubernetes’s metric server.
-
The customer’s monitoring platform was built on Datadog and was used extensively for monitoring. Kubernetes’s native horizontal pod, autoscaler only integrated with the metric server for which there was no Datadog integration available.
-
The path to building a horizontal pod autoscaler was not clear. After the first consultation with InfraCloud, customer discovered the entire pipeline built of adapters for the newly introduced metric server. But during implementation, we found a better path of implementation – which would mean pivoting to a different design than earlier envisioned.
Solutions Deployed
Autoscaling of Kubernetes Application – Pod Autoscaling
InfraCloud designed an end-to-end monitoring pipeline, as shown in the diagram below, using two adapters. The first adapter enabled passing metrics from Statsd agent to Prometheus by doing the appropriate conversion. The second adapter converted metrics from Prometheus to metric server format. This total pipeline allows custom metrics passed from application to metric server to be scaled.
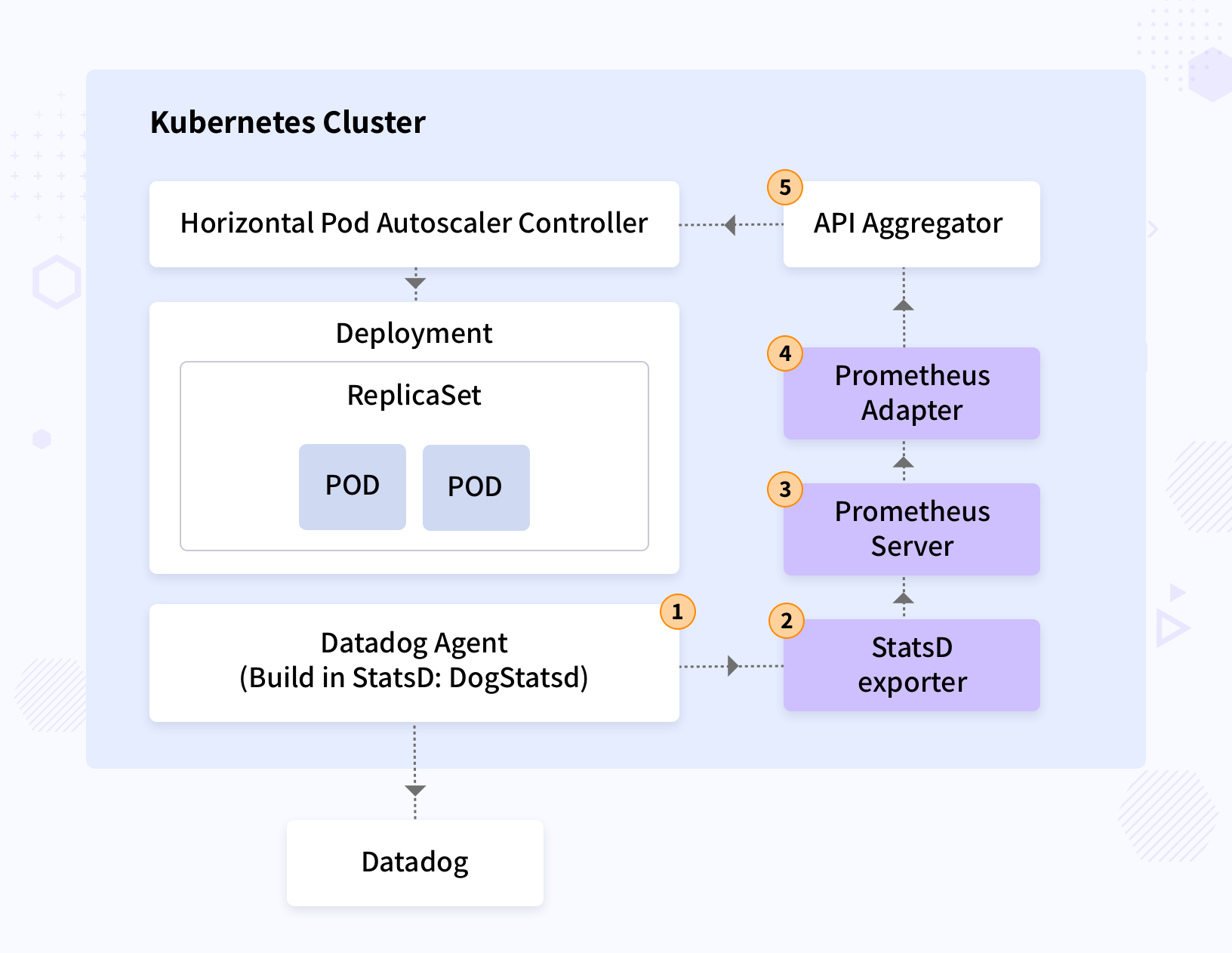
While the implementation started based on initial design and testing was being carried out Datadog introduced the metric server compliant “Datadog cluster agent”. This would simplify the pipeline drastically by removing components and would also be supported by the provider. Infracloud recommended switching to a new design for simplicity. The implementation was then changed to a new architecture, as shown in the diagram below.
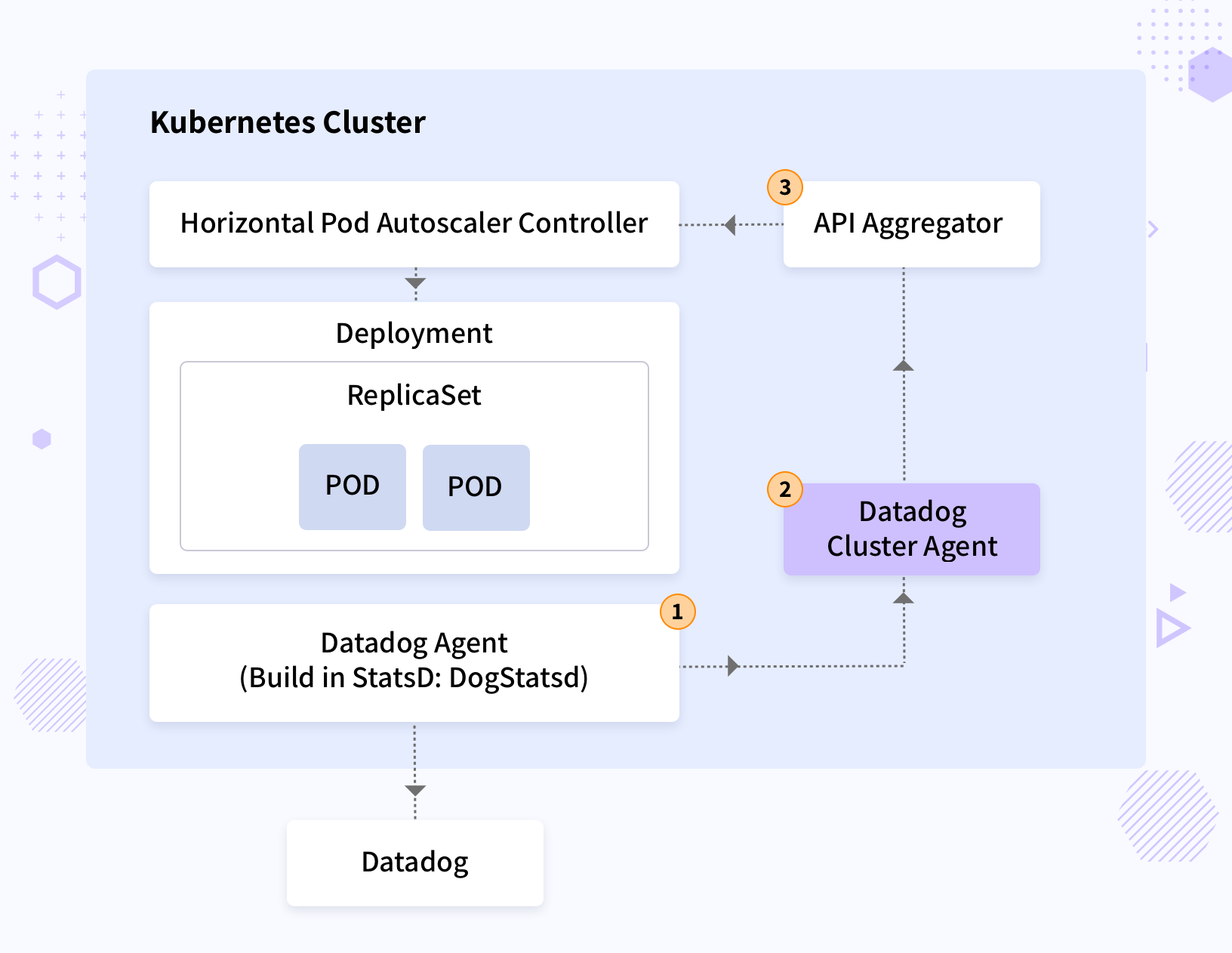
Node Autoscaling
For scaling the nodes, we evaluated two options:
Escalator - An open source node autoscale from Atlassian.
Kubernetes Autoscaler - the official node autoscaler from Kubernetes community.
All requirements were evaluated and with a quick PoC, the Kubernetes Autoscaler was chosen as the go-to tool. Kubernetes autoscaler enabled scaling of nodes in clusters based on the resource needs of the application. Scaling up and scaling down policies were defined along with pod disruption budgets for each application.
Benefits
-
Autoscaling helped the customer to scale the worker application instances based on messages in queue even though Datadog at that point did not support integration with autoscaling servers of Kubernetes.
-
With node autoscaler in place, the cost of infrastructure was optimised to the current resources in use and thus, overall cost saving was achieved.
Why InfraCloud?
- Our long history in programmable infrastructure space from VMs to containers give us an edge.
- We are one of cloud native technology thought leaders - speakers at various global CNCF conferences, authors, etc..
- DevOps engineers who have pioneered DevOps at Fortune 500 companies.
- Our teams have worked from data center to deploying apps and across all phases of SDLC, bringing a holistic view of systems.
Got a Question or Need Expert Advise?
Schedule a 30 mins chat with our experts to discuss more.




