Monitoring Edge Devices at Scale with Prometheus and Thanos

Client Details
The company is a networking devices company which deploys hardware devices ranging from 100s to 1000s for their customers. Each of these device’s health needs to be reported with vital metrics so that anomalies can be detected and fixed.
Context & Challenges
The customer had built a monitoring pipeline with a custom agent that integrated with Prometheus and AlertManager. This system worked well but as the scale of devices and the metrics they reported increased, the system started performing poorly. The issues specifically were:
- As the number of devices & metrics would grow, the memory and CPU consumption of Prometheus would grow non-linearly. Thus the provisioned capacity was not enough as the scale of the infrastructure grew.
- Prometheus also started crashing under heavy load and could not sustain the scale of data to be handled.
- The customer knew that Prometheus was not built for high availability and needed HA & sharding. They had explored projects in the community such as Cortex and Thanos but they did not have expertise in-house to understand and implement these technologies.
Customer reached out to InfraCloud based on their work and blog comparing Cortex and Thanos for scaling monitoring pipelines.
Proof of Concept:
With the initial engagement customer wanted a proof of concept that either Cortex Project or the Thanos project could scale to the needs of customer’s scale. This was crucial before investing more energy and resources in the technology. The goals of POC were:
- Prove that Cortex or Thanos can scale to current and future needs of 1000s of devices emitting ~500 metrics at every scrape (Which is equivalent of 500,000 metrics every scrape)
- Prove this in a lab environment with appropriate changes to the architecture, configurations of software and tuning of underlying infrastructure resources such as OS parameters.
Solutions Deployed
Iterating to the scalable solution
InfraCloud team’s POC collaboration was successful and the customer wanted to further collaborate on taking the implementation to its full deployment and scale for real workloads. The scale needs were even higher now and that would mean the architecture would need to be further tweaked. As part of this work, four different architecture were evaluated:
- Functional sharding of Prometheus data using Kafka consumer groups
- Using sharding at exporter level and read data across sharded Prometheus
- Using sharding at exporter level but Thanks for alert evaluation globally
- Using sharding at the exporter level while using federation for metric aggregation.
In each of the approaches it was important to consider & evaluate:
- How will custom exporter & Prometheus run and scale
- Will aggregation across shards creates queries which are very complex.
- There should be no single point of failure.
- Scaling up/down a certain component should minimize triggering of Kafka rebalance - as it might result in Kafka cluster instability.
- Querying and alerting should work reliably in 99%+ use cases.
After carefully evaluating each approach in the context of the customer’s use case and scale, two architectures were chosen for deploying and testing for scaling.
The final pipeline implemented is described in the following diagram.
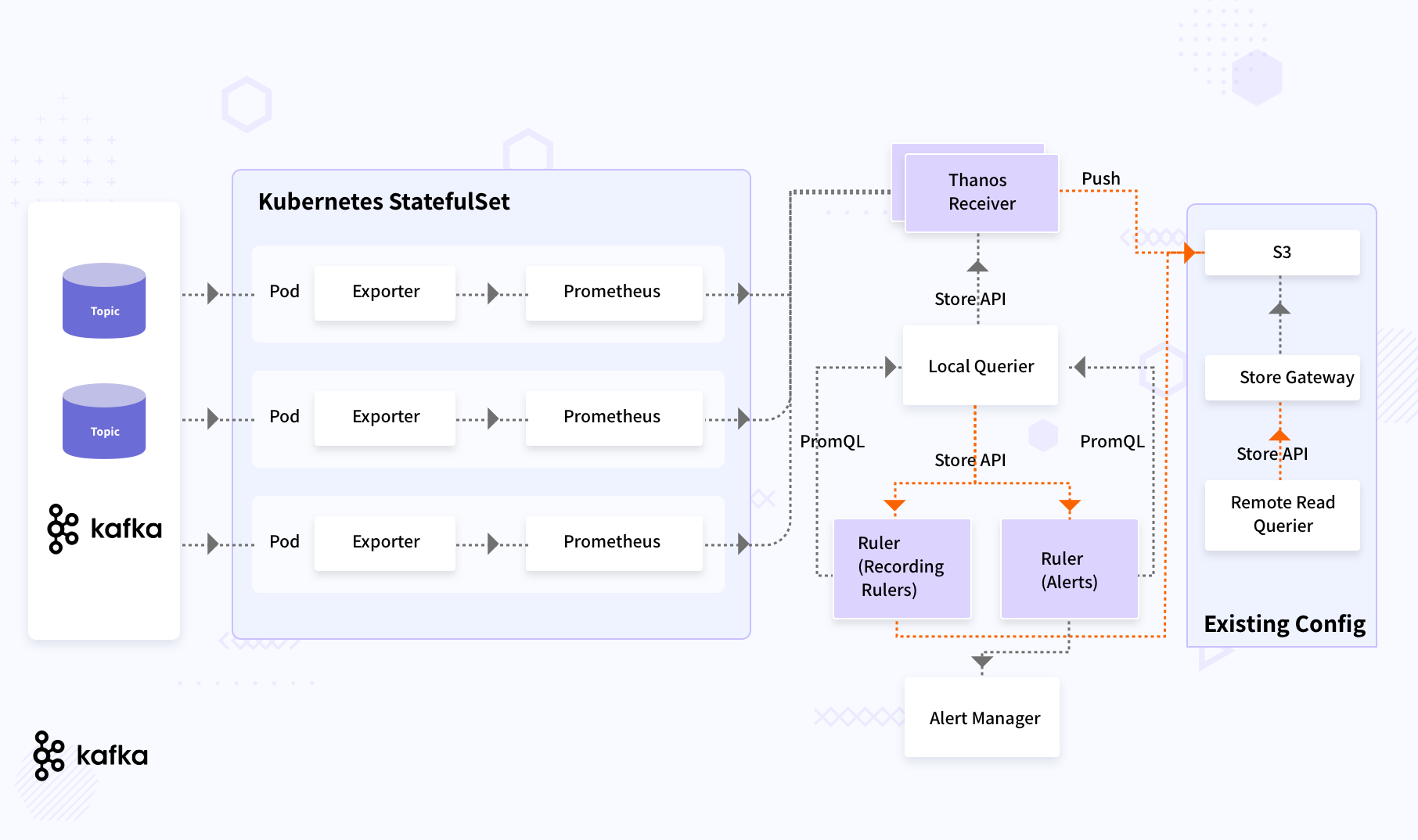
Benefits
-
Customer was able to scrape more than 1/2 Million metrics per scrape from their devices without any issues or pressure onto the system.
-
This scaling of monitoring pipeline was a crucial factor for the customer’s SaaS journey and product launch in next financial year.
Why InfraCloud?
- Our long history in programmable infrastructure space from VMs to containers give us an edge.
- We are one of cloud native technology thought leaders (speakers at various global CNCF conferences, authors, etc.).
- DevOps engineers who have pioneered DevOps at Fortune 500 companies.
- Our teams have worked from data center to deploying apps to cloud and across all phases of SDLC, bringing a holistic view of systems.
Got a Question or Need Expert Advise?
Schedule a 30 mins chat with our experts to discuss more.




