Serverless Architecture for Analytics Data Pipeline

Client Details
The customer is an IOT company with multiple large industrial customers using their data analytics and services platform.
Context
The customer wanted to reduce the data pipeline cost, where effective utilization was much lesser than the system’s static capacity.
Challenges
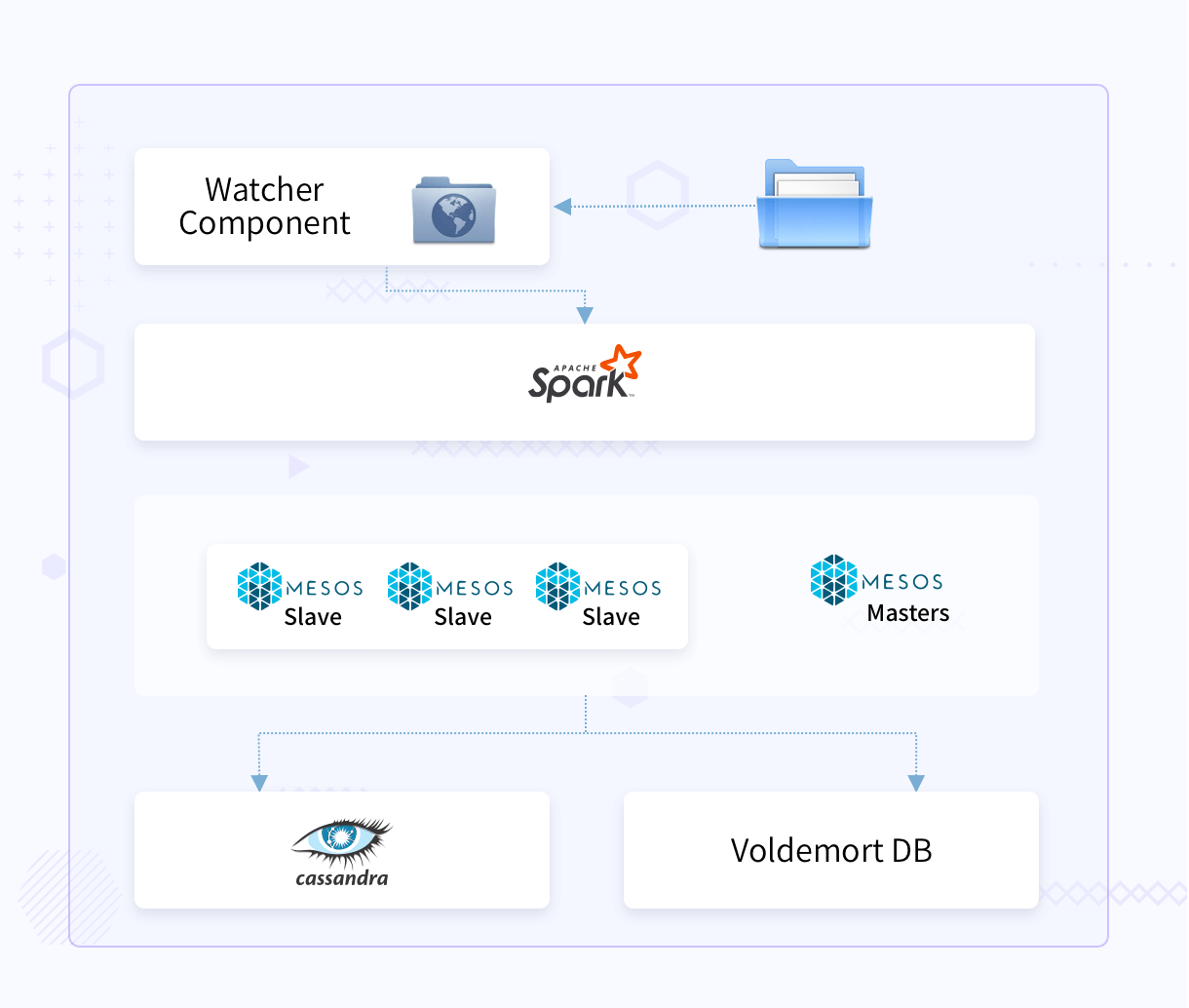
The customer had a platform that received a large amount of text data at periodic intervals. A daemon component picked up the file as they arrived and then called spark workflow to analyze the data. Spark pipeline analyzed the data and stored part of Cassandra’s results and part of Voldemort DB results.
Although the data ingestion was periodic (Up to 3 times an hour), the infrastructure required, such as the watcher component and Spark workflow on top of Mesos framework, consumed large capacity but sat idle for most of the time.
The customer approached us for a solution to this problem, and we proposed a serverless model. This case study describes the details of the solution and effective cost savings derived from the transformation.
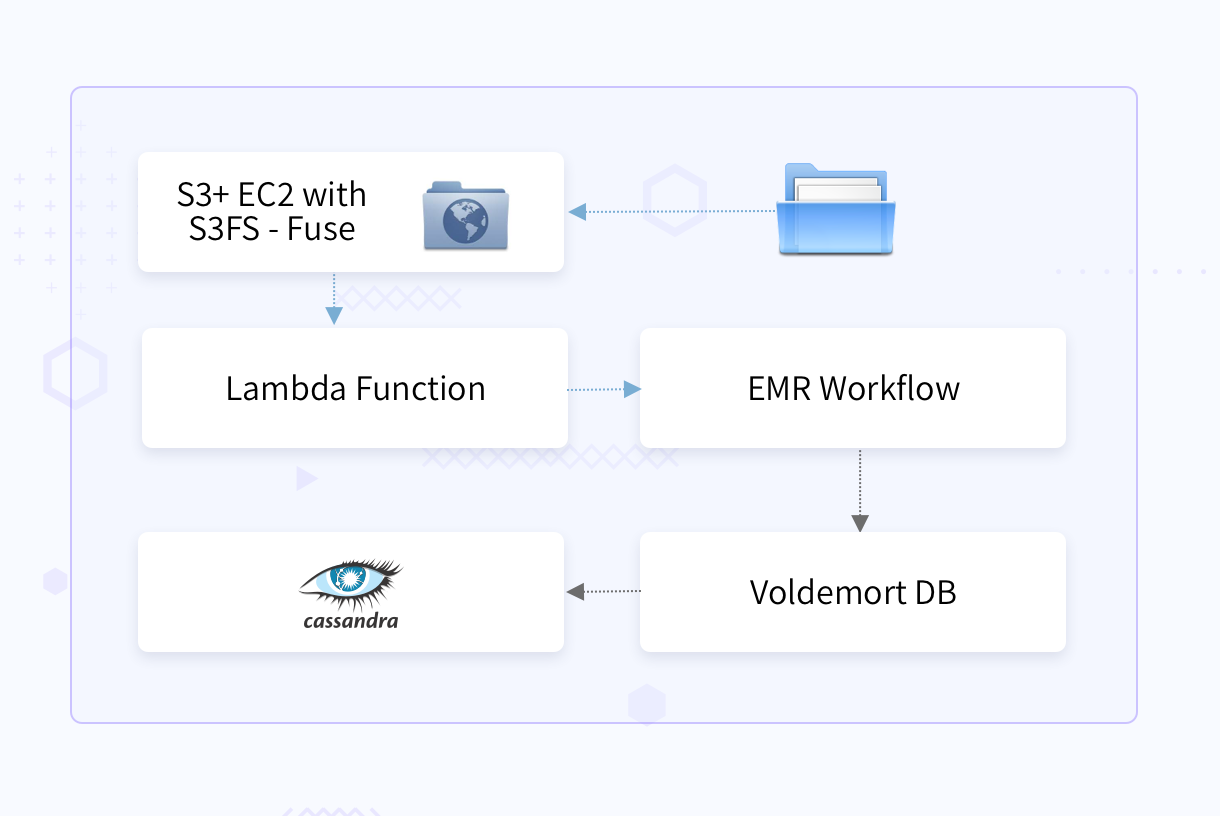
Solution
The S3 buckets were mounted on an EC2 instance and exposed as an FTP server using the S3FS-Fuse project to keep the end-user interface the same.
A new file in S3 triggered the lambda function, which did a quick verification of filename syntax and then invoked the EMR workflow. The EMR workflow did the Spark analysis and then stored results into Cassandra and the Voldemort DB.
One of the critical areas during implementation was how to define the application model for serverless architecture. Although CloudFormation was an option, we ruled out due to the complexity of writing CloudFormation spec. After trying out, we recommended and used the Serverless framework (www.serverless.com), which concisely defines the whole application model and converts it to CloudFormation.
This POC’s success leads the management to seriously consider serverless and revisiting all organizations’ applications to access fit to the serverless framework.
Key Highlights
Drastic reduction in static un-utilized infrastructure costs. In peak times, the savings were as much as 40%, and at non-peak times, close to 70%. Overall far simpler management of tasks and workflow.
Why InfraCloud?
- Our long history in programmable infrastructure space from VMs to containers give us an edge.
- We are one of cloud native technology thought leaders (speakers at various global CNCF conferences, authors, etc.).
- DevOps engineers who have pioneered DevOps at Fortune 500 companies.
- Our teams have worked from data center to deploying apps and across all phases of SDLC, bringing a holistic view of systems.
Got a Question or Need Expert Advise?
Schedule a 30 mins chat with our experts to discuss more.




