API-First Way of Building Internal Developer Platforms
 Ruturaj Kadikar
Ruturaj Kadikar  Ninad Desai
Ninad Desai A strong internal developer platform (IDP) takes care of the accessibility issues and abstracts away the pipeline sprawl. Even newcomers can get to “hello world” without scavenging a repo with the paved path. But here’s the catch: too often, IDPs lean heavily on portals. They add platforms’ elements like shiny dashboards, discovery tools, and templates without wiring them to the actual core capabilities or the muscle that makes workflows seamless.
Code itself isn’t the hard part. The system wrapped around it is. Platforms don’t fail because of a lack of polish on the UI. They lack the muscle, i.e., the APIs and application layer that actually move work forward.
If using the platform is harder than skipping it, developers will skip it.
Portals are faces. Platforms are muscle.
We love a good portal. But a portal without muscle is a showroom with no factory. Imagine a portal that doesn’t have any helpful documents or usable templates. Teams will click around, admire the catalog, and then… go back to hand-rolled scripts because the heavy lifting isn’t actually wired up.
Muscle-first flips the sequence:
-
Build an application/API layer that encapsulates the workflows, policy, and security you want every team to enjoy.
-
Expose that muscle through thin faces: a portal, a CLI, ChatOps—whatever the team prefers.
-
Keep the faces lightweight so they can evolve; keep the muscle strong so the experience is consistent, auditable, and reliable.
With this approach, adoption will stop needing mandates. Engineers will choose the golden path because it is much smoother and faster.
Muscle of the Platform: The Execution Layer That Changes Everything
In API-first approach, the muscle sits as a service layer (any framework of your choice, like GraphQL/FastAPI, etc, behind auth) that any interface can call. Here’s what it centralizes:
Golden-path workflows: The platform provides end-to-end flows your teams care about: service bootstrap → CI → GitOps deployment. It doesn’t just mint files; it orchestrates the steps with idempotence and guardrails. The easy paths become the correct path that provides developers the quickest and cleanest way to deploy services.
Auth, audit, policy: Compliance and guardrails are a cornerstone of platforms. Who can do what, when, and where is enforced in one place to ensure conformance to standards, best practices, and regulatory requirements. Every action is logged. Options are provided to handle any explicit requirement, making the platform flexible.
Self-service infrastructure: Developers provide intent - “I need a bucket for logs”, not 40 lines of IaC. The platform maps this intent to org-approved Terraform/Crossplane modules with encryption, tagging, and naming baked in. This ensures the developers get what they need when needed and prevents them from getting into an approval loop with the IT team.
Day-0 observability: Observability is integrated into the platform. Telemetry and baseline dashboards attach automatically when a service is created. Developers see latency, errors, and throughput on the first deployment, not the fifth incident.
Explainable abstractions: Every “easy button” links to “what got created” and “how to override safely.” Abstraction without explanation is a trap. Abstractions that help new developers get started quickly while providing escape latches to architects who want more control over their deployments.
All of this execution muscle gives developers speed and safety, but it also raises a design question: how do you decide what belongs inside the platform’s muscle and what should remain outside, left to team choice? Put too much in the core and you risk rigidity. Leave too much out and you lose reliability.
Core vs. Flexible Periphery: reliability with autonomy
The muscle defines the core: golden paths, auth, audit, and observability that must be consistent everywhere. The periphery is where teams can choose their own frameworks, databases, or eventing tools, so long as they connect through clean, reliable interfaces. The balance between core and periphery gives platforms trust and autonomy.
That balance avoids the two classic failure modes:
-
Cages: Over abstracted portals that collapse during incidents. E.g., A platform team forces every service onto a single CI/CD pipeline template. When a team needs GPU jobs, the template breaks. No way out → platform adoption stalls.
-
Chaos: Every team invents pipelines, policies, and infra shapes from scratch. E.g., A large enterprise lets each app team choose any CI/CD tool. Jenkins, GitHub Actions, and CircleCI are used by various teams with different secrets management, audit logs, and naming. Debugging production issues takes days because no two systems behave alike.
Golden paths are the middle way: attractive to use, trivial to leave when justified.
To avoid both cages and chaos, a polished portal wasn’t enough; we needed muscle. This is the turn we made. Let’s walk-through our experience of building IDP for one of our many customers.
Don’t ship a showroom. Ship a factory floor.
We made the classic mistake first: portal-first. Backstage looked great; usage spiked for a week, then flattened. Pairing with devs revealed why: “Nice surface, but the heavy lifting isn’t wired up.” So we flipped the order to API-first and built the muscle.
What we actually built (the muscle)
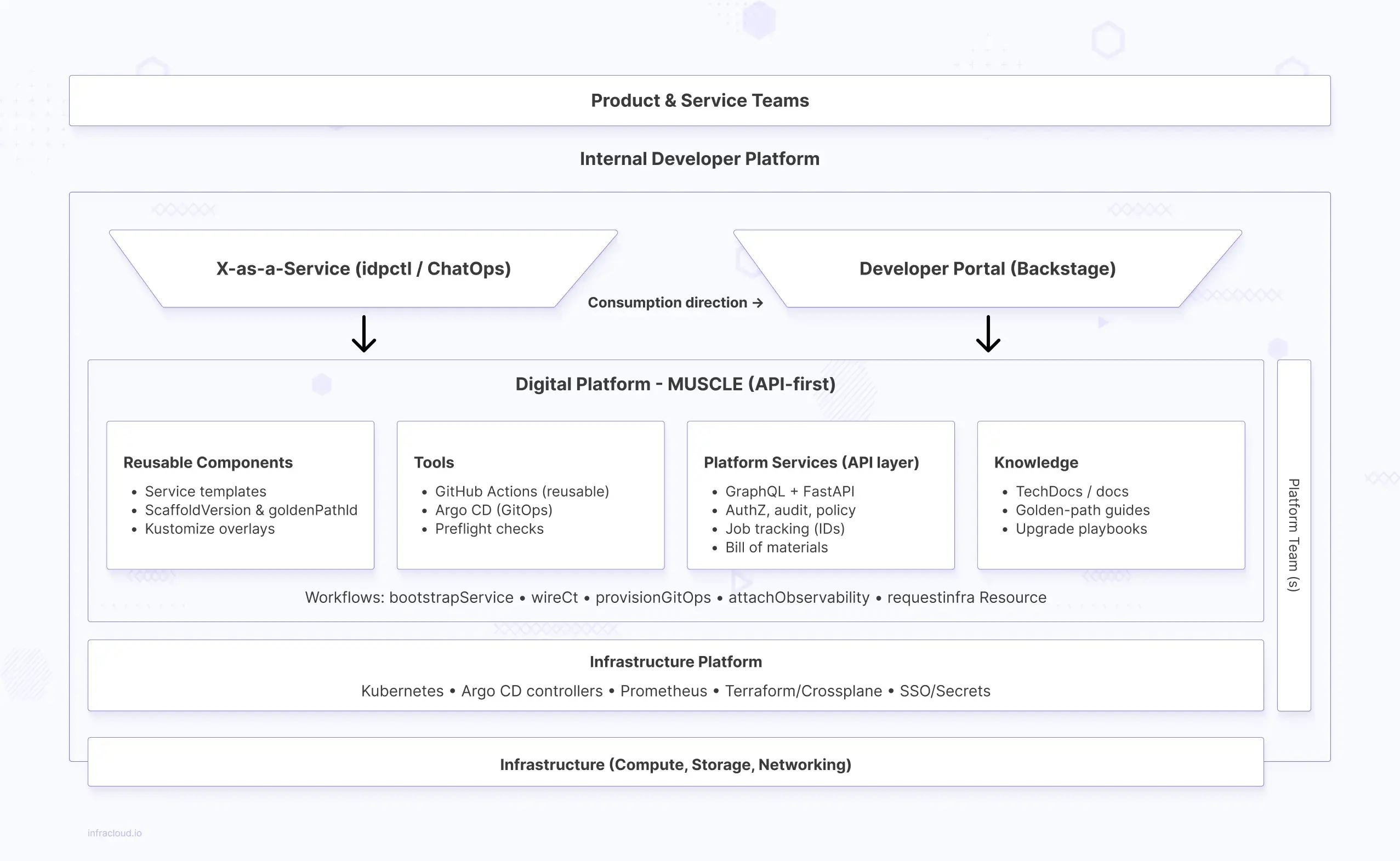
-
A backend service (GraphQL + FastAPI as we had skills around them) behind org SSO that exposes idempotent endpoints for:
bootstrapService → wireCI → provisionGitOps → attachObservability → requestInfraResource -
A single policy point: authZ, audit, naming/labeling conventions, cost tags, and environment protections live here.
-
Template versioning: every scaffold stamps a
scaffoldVersionandgoldenPathId, so we can upgrade older services safely. -
Dual faces, one backend: Backstage plugin and CLI call the same endpoints, so UI/terminal parity is guaranteed.
What our developers saw (one thin flow, end-to-end)
-
Create service → repo with sensible skeleton, unit test, Dockerfile, standard CI, security baselines, and day-0 instrumentation pre-wired.
-
Deploy with GitOps → the backend generates an Argo CD Application and manifests with consistent labels, SLO hooks, and cost tags; PR → merge → deploy.
-
Open dashboards → baseline Grafana board appears automatically (latency, errors, RPS, plus app metrics).
-
Ask for S3 (or RDS, etc.) → dev provides minimal intent; backend maps it to vetted Terraform/Crossplane modules (encryption, tagging, policies enforced by default).
Why did adoption pick up:
-
Channel-agnostic access (UI/CLI parity): Teams could choose the interface that fits their workflow without learning two different behaviors. The Backstage plugin and CLI invoked the same routes, so docs, demos, and runbooks worked everywhere. This cut training overhead and removed a common “but the button vs. the script” drift.
-
Lower cognitive load via golden paths: Instead of assembling boilerplate, secrets, pipelines, and IaC manually, devs followed a single golden path that made secure defaults the path of least resistance. Standard repo shape, pre-wired CI, and opinionated IaC meant fewer forks, fewer decisions, and dramatically less tool-hopping.
-
Faster feedback loops from day one: Preflight checks and seeded CI trimmed the “first build” and “first deploy” loops. Day-0 observability meant the first request showed up on a dashboard - no extra tickets or manual wiring - so teams could iterate while momentum was high.
-
Operational trust (policy + audit in one place): Authorization, tagging, naming, and environment protections live in the muscle. Every action was logged, every exception explicit. Platform/infra and security could verify posture without slowing devs.
-
Evolvability without rewrites: We could add new golden-path steps (or update templates) in the backend and get the improvement in both UI and CLI instantly. Conversely, we could tweak the UI without touching the workflows.
scaffoldVersionand theidp upgradeflow let early services catch up safely. -
Onboarding that actually starts work: Because access, scaffolding, CI, and dashboards came alive in one flow, new hires moved from “waiting on tickets” to “pushing a PR” quickly. Less Slack back-and-forth, more shipping.
Adoption didn’t grow because we mandated it. It grew because we earned it.
If you’re starting (or rebooting) your IDP journey, here’s how to take the first slice without boiling the ocean.
Build Your Platform
If you are building your platform, these tips will help you build a successful one.
Observe before you abstract: Shadow your developers to understand their usage of tools, processes, and painpoints. Observe them all, whether it’s a new hire or your most experienced architect. Count waits, handoffs, and tool switches. Write the top three shared friction points as jobs-to-be-done.
Ship the thinnest viable platform: Based on your analysis, choose the most common task your developers perform on your platform and create a golden path for it - create service → CI → GitOps → day-0 telemetry - and make it excellent. Resist supporting “every stack” from the word go.
Build muscle, then face: Your platform’s core is its capabilities. Focus on making robust capabilities first. Create the API layer that triggers workflows and enforces policy. Once the capabilities are in, wire Backstage and a CLI on top. Keep the faces thin, functional, and ensure that everything that developers need is easily accessible.
Market internally: What’s the use of building a platform when nobody knows about it? Plan internal roadshows and communications about new releases, run live demos, publish “what changed” notes, and market your platform. Celebrate teams that got faster because they used the platform. Turn users into advocates and champions.
Design for exceptions: Golden paths must be the easiest paths, but not mandatory. Platforms are not only about tools. Not every developer needs the default settings to build their services. Senior developers and architects need more configurable options in the same golden path. Provide latches but with proper checks, reviews, and logging.
Measure outcomes, not outputs
It’s easy to count YAML lines and portal clicks; neither proves you removed friction. What matters is whether teams can deliver with less drag and more safety. To see this, blend delivery and experience signals:
Lead time & deployment frequency: These show the flow of work through your system. If changes move from idea to production faster and teams can deploy more often with confidence, you’ve reduced bottlenecks. For example, a commit taking hours instead of days to reach production is a clear signal of healthier delivery flow.
Change failure rate & MTTR: These indicate whether your safety nets are working. Shipping quickly means little if every second release breaks production. A low failure rate plus a fast mean time to recovery (like rolling back or patching within an hour) demonstrates that guardrails are real, not just policy.
Feedback loop time: The faster developers get feedback, the easier it is to maintain momentum. Waiting 30 minutes for a build versus 3-5 minutes is the difference between staying in flow and switching context. Bloated build times often act as a hidden tax on velocity.
Cognitive load: Every extra tool, login, or step adds friction. Mental overhead is high if developers need five dashboards and three approvals just to release a fix. Teams with lower cognitive load can focus on delivering value instead of navigating complexity.
Adoption: The best signals come from what teams choose, not what leaders mandate. You’ve earned trust if most developers use the “golden path” CI/CD pipeline without hacks or workarounds. Conversely, lots of bypassing (custom scripts, shadow pipelines) suggest the paved path doesn’t meet real-world needs. Adoption, therefore, is a measure of trust in the platform.
All these numbers point you to patterns. The conversations and interviews explain the “why” behind them. You need to know both to learn whether you’re truly removing friction.
Why API-first wins adoption?
Measuring flow, failure, and feedback loops is useful only if it informs the mechanism. For us, that mechanism was an API-first platform.
Channel-agnostic: The same capabilities are reachable from UI, CLI, or chat. You’re not forcing behavior; you’re meeting teams where they are.
Lower cognitive load: Developers stop being amateur release engineers. They express intent; the platform does the plumbing.
Operational trust: Security, audit, and policy live in one place, not five forks of a script.
Evolvability: You can add features to the muscle without rewriting the face. Or change faces (Backstage → custom UI) without touching the muscle.
Explainability: When something goes sideways, engineers can drill down from the golden path to raw artifacts and logs. No black boxes.
Antipatterns to dodge
These are some antipatterns you would like to avoid:
Portal-as-platform: A UI is best treated as a friendly face, not the heart of the platform. The real power lies in APIs, automation, and the raw capabilities underneath. If all the logic lives only in the portal, you create a bottleneck and limit how developers can scale or script workflows.
Abstracting before you observe: Creating abstractions without understanding real developer pain often leads to the wrong details being hidden. For example, assuming everyone needs a generic “deploy” button without studying how teams actually ship may oversimplify or block critical steps. Spend time watching the day-to-day flow before masking complexity.
Gatekeeping in disguise: If your golden path is slower or clunkier than the workarounds, developers will naturally bypass it. A “secure pipeline” that takes 30 minutes versus a script that ships in 3 will never win adoption. The golden path must be safer and faster, or it becomes gatekeeping masquerading as governance.
Policy by wiki: Policies written in documentation are rarely followed if the tooling doesn’t enforce them. Expecting developers to remember and apply rules manually guarantees drift. Instead, build guardrails directly into templates, workflows, and CI/CD checks so compliance happens by default, without relying on a wiki page.
Consider the platform as a product
An internal developer platform isn’t a stack of tools. It’s a product with real users who sit a few desks away. Build the muscle first so the face, whatever face you choose, has something worth smiling about.
- Think like a product manager (research, roadmap, adoption).
- Work like a partner (co-design with teams, invite contributions).
- Deliver like a platform engineer (secure, reliable, observable by default).
If you want the whole tour, golden paths vs. cages, the reference architecture, and a live walkthrough of the muscle-and-faces approach, watch the talk by Ninad and Ruturaj that they delivered at KubeCon. If you’re starting this journey now, start small: one thin slice, shipped well. Everything good flows from there.
We hope this article helps you understand the theory of building platforms, but things are even more complicated in real life. If you get stuck at any stage, feel free to contact our expert platform engineers to take a look.
References:
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like







