
Batch Scheduling on Kubernetes: Comparing Apache YuniKorn, Volcano.sh, and Kueue

Batch processing plays a vital role in many modern systems, especially for data processing, machine learning training, ETL, etc. Kubernetes, while historically designed for long-running services, has expanded its capabilities to support these batch workloads. With the help of specialized tools, Kubernetes has become a robust platform for handling resource-intensive and time-sensitive tasks.
In this blog post, we will dive into batch scheduling on Kubernetes, the challenges it entails, and compare three powerful open-source tools - Apache YuniKorn, Volcano.sh, and Kueue - that cater to batch scheduling needs.
Introduction to batch processing on Kubernetes
Batch processing refers to executing a series of tasks or jobs without requiring immediate mannual interaction. Jobs like data transformation, building software in CI/CD workflows, or running AI/ML training typically fall under batch processing. Unlike traditional workloads, such as APIs or databases that run continuously and focus on uptime, batch workloads are:
- Finite in nature, running for a fixed duration, and then terminating.
- Resource-heavy, often requiring large, bursty allocations of CPU, memory, or GPUs.
- Dependency-driven, with tasks needing to execute in a specific order or framework, like parallel execution.
With its evolving ecosystem, Kubernetes has become the go-to orchestrator for running batch jobs. However, the default Kubernetes scheduler, designed for general-purpose workloads, struggles with certain nuances of batch processing.
Challenges in batch scheduling on Kubernetes
Batch scheduling has some fundamentally different requirements compared to normal workloads. A good batch scheduling tool is designed to mitigate these challenges effectively. Here’s a look at common challenges in batch scheduling and how robust tools can resolve them:
Resource contention
Batch workloads often compete for limited resources like GPUs, which can lead to inefficiencies or deadlocks. For example, in a multi-tenant AI/ML environment where resources are shared, if Team A runs low-priority job followed by Team B’s high-priority job, just because the job was run earlier, the low-priority job can obstruct the high-priority job due to limited resources getting blocked. It works on a first-come, first-served basis, without considering priorities. To address this, tools should implement fair scheduling and resource quotas to ensure resources are shared proportionally among teams, preventing any single workload from monopolizing resources.
Gang scheduling
Distributed tasks like ML model training require all associated pods to start simultaneously. Without coordination, resource wastage becomes inevitable. A good tool provides gang scheduling, ensuring simultaneous resource allocation for all tasks in a job to avoid partial execution.
Dependency handling
Many batch workflows consist of interdependent tasks where one cannot begin until another completes. For example, in ETL jobs, the extraction must be completed before the transformative job can run, or in CI/CD jobs, the build must happen before the deployment job is triggered. Tools that support workflow dependencies ensure seamless execution by automatically scheduling tasks in the correct order.
Job prioritization
Not all jobs have the same urgency. Critical jobs should preempt less important ones to meet business-critical deadlines. A job running critical functionality should be able to take priority over a regular non-critical job; to achieve this, we should be able to tag jobs based on their priority. Effective tools enable priority-based scheduling and preemption, dynamically rescheduling resources to accommodate high-priority workloads without delay.
Scalability
Kubernetes clusters handling hundreds or thousands of batch jobs require scalable solutions. Batch scheduling tools must efficiently manage large-scale workloads, optimizing cluster-wide resources without breaking under pressure.
Multi tenancy
Shared environments introduce complexities where multiple teams or projects need equitable resource access. Tools with multi-tenancy support ensure fair resource distribution, often through hierarchical queues, ensuring workloads from different users coexist peacefully. For example, a company with a shared Kubernetes cluster with 100 GPUs may need to share it with multiple teams like NLP, data science, and Analytics, with the condition that 50% of the GPUs are reserved for the NLP team.
By bridging these gaps, specialized tools enhance the capacity of Kubernetes to execute batch workloads effectively, reducing inefficiencies and improving overall cluster health.
Available tools for batch scheduling on Kubernetes
Several open-source tools aim to bridge the gap left by Kubernetes’ default scheduler. Let’s examine the three key players: Apache Yunikorn, Volcano, and Kueue:
1. Apache YuniKorn: Supports both batch and non-batch workloads
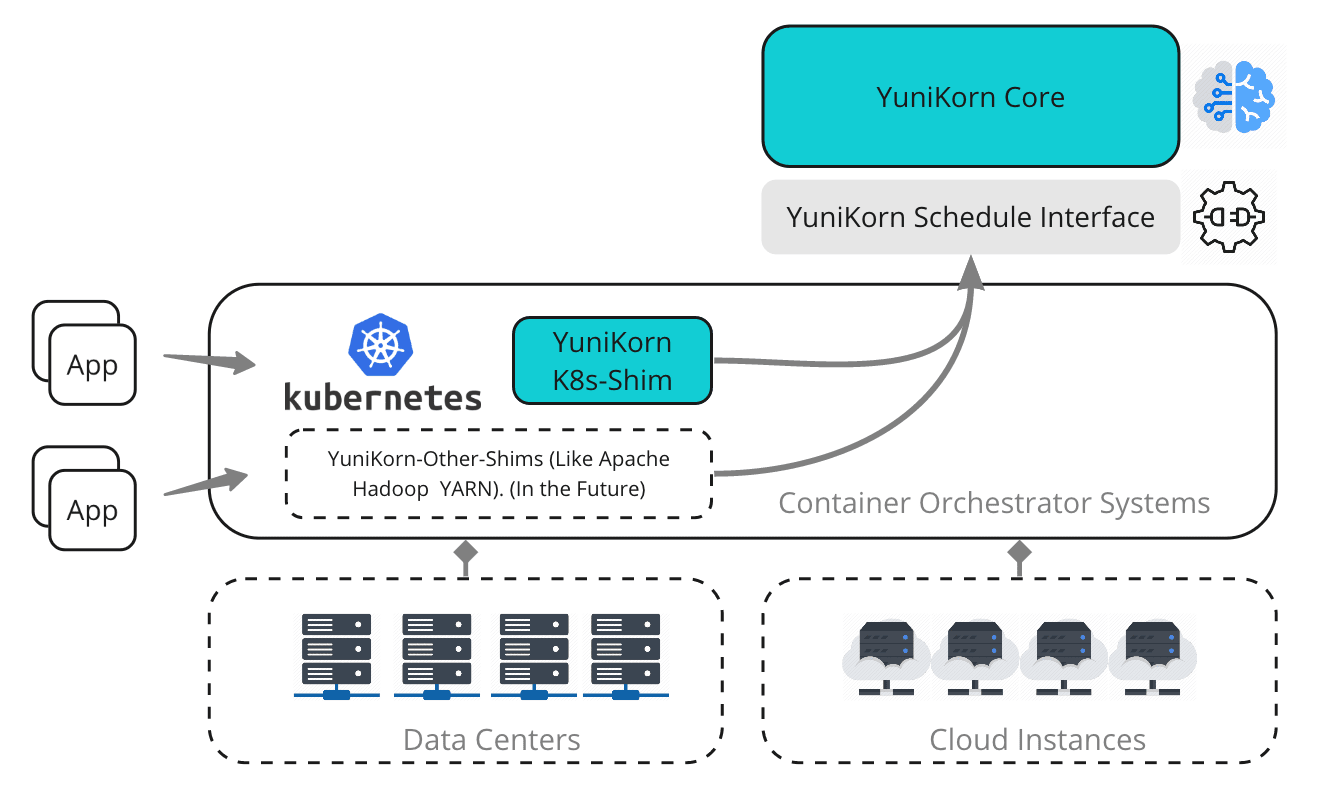
Apache YuniKorn is a universal scheduler for Kubernetes and other platforms, focusing on multi-tenant resource sharing. It is designed to replace the default Kubernetes scheduler and seamlessly supports batch and non-batch workloads.
- Documentation: To get started with Apache YuniKorn, explore the official documentation here.
- Strengths: Unified scheduling for batch and service workloads, hierarchical queues, and fairness policies.
Use case: Multi-tenant clusters requiring hierarchical resource sharing and fairness. The below example shows how Apache YuniKorn helps with setting up queues for resource management in multi-tenant environment and allows fair scheduling (efficient resource dedication).
kind: ConfigMap
metadata:
name: yunikorn-configs
namespace: yunikorn
apiVersion: v1
data:
admissionController.accessControl.externalGroups: "admin,^group-$"
queues.yaml: |
partitions:
- name: default
queues:
- name: root
queues:
- name: system
adminacl: " admin"
resources:
guaranteed:
{memory: 2G, vcore: 2}
max:
{memory: 6G, vcore: 6}
- name: tenants
resources:
guaranteed:
{memory: 2G, vcore: 2}
max:
{memory: 4G, vcore: 8}
queues:
- name: group-a
adminacl: " group-a"
resources:
guaranteed:
{memory: 1G, vcore: 1}
max:
{memory: 2G, vcore: 4}
- name: group-b
adminacl: " group-b"
resources:
guaranteed:
{memory: 1G, vcore: 1}
max:
{memory: 2G, vcore: 4}
2. Volcano.sh: Best for high performance workloads
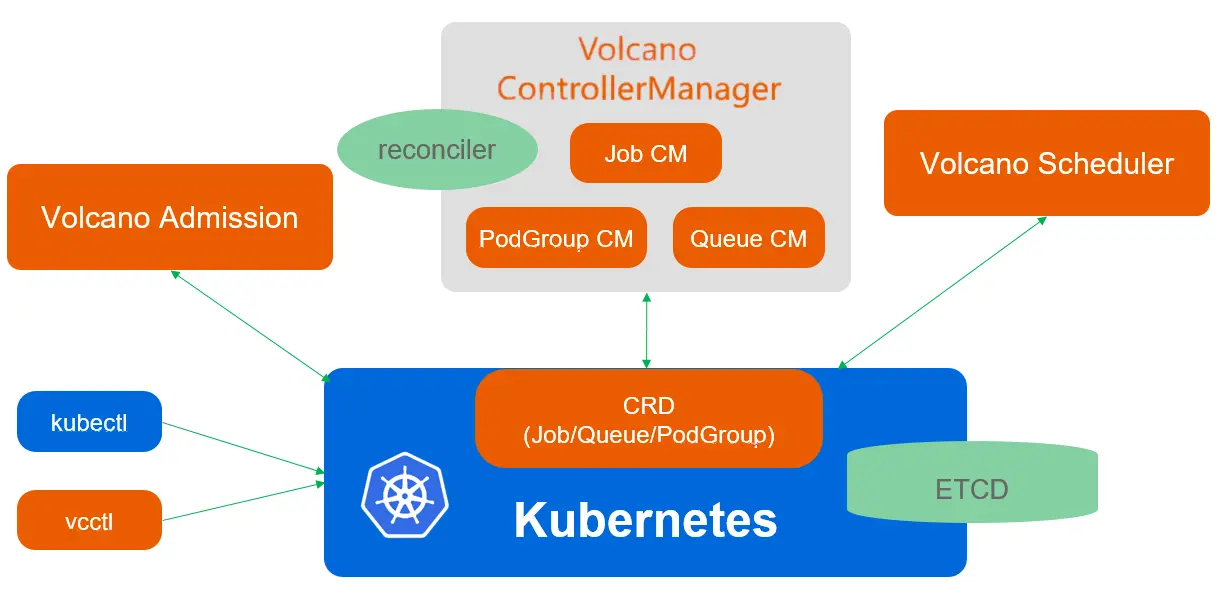
Volcano is a batch scheduling system designed for high-performance workloads like AI/ML, deep learning, and big data processing. Volcano supports popular computing frameworks such as Spark, TensorFlow, PyTorch, Flink, Argo, MindSpore, Ray, and PaddlePaddle. Unlike Apache Yunikorn, Volcano works alongside Kubernetes’ default scheduler.
- Documentation: Learn more about using Volcano in its official documentation.
- Strengths: Gang scheduling, resource bin packing, and managing job dependencies.
Use case: Resource-intensive workloads requiring advanced scheduling policies. The capabilities of Volcano make it popular in AI and big data applications. For running machine learning workloads, teams often need to schedule hundreds of GPU-intensive training jobs that compete for limited GPU resources.
Standard Kubernetes schedulers operate at the pod level, leading to resource fragmentation and inefficient GPU usage. Volcano solves this by introducing gang scheduling - ensuring that either all pods in a job are scheduled simultaneously, or none are. This avoids partial resource allocation, which is critical for parallel jobs like distributed training (e.g., TensorFlow, PyTorch). The code snippet below shows how Volcano can help with it:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: tf-training
spec:
minAvailable: 4 # Gang scheduling: all 4 pods must be scheduled together
schedulerName: volcano
tasks:
- replicas: 4
name: worker
template:
spec:
containers:
- image: tensorflow/tensorflow:latest
name: tensorflow-worker
restartPolicy: Never
3. Kueue
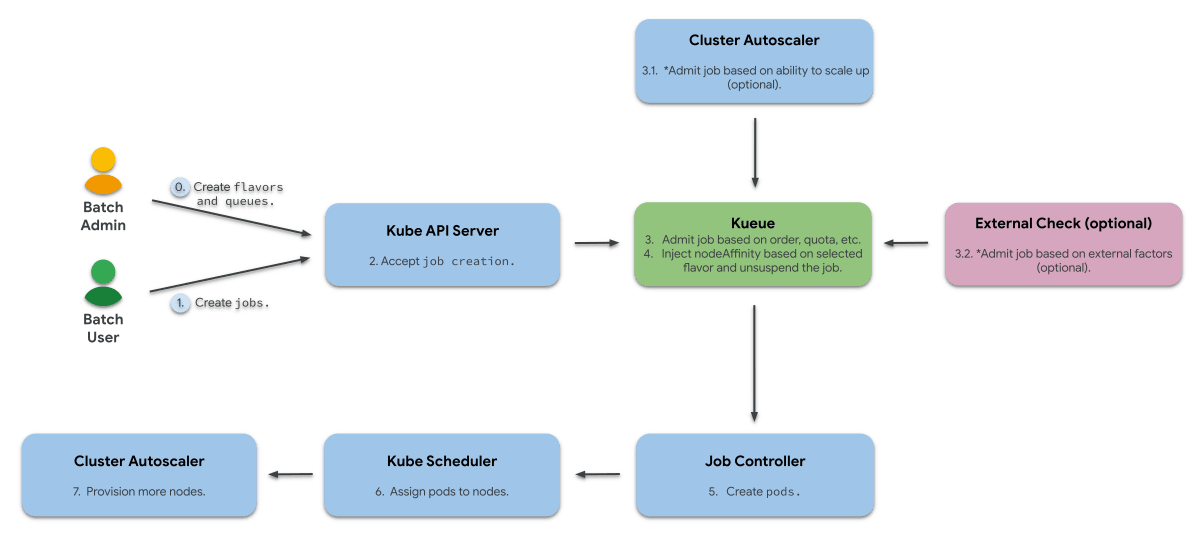
Kueue is a Kubernetes-native job queueing system built for batch workloads. It focuses on managing job queues, resource quotas, and priorities while complementing the Kubernetes ecosystem.
- Documentation: Learn more about Kueue from the official documentation.
- Strengths: Native Kubernetes integration, resource reservation, and priority-based scheduling.
Video description: With the skyrocketing demand for GPUs and problems with obtaining the hardware in requested quantities in desired locations, the need for multicluster batch jobs is stronger than ever. During this talk, Ricardo Rocha & Marcin Wielgus show how you can automatically find the needed capacity across multiple clusters, regions, or clouds, dispatch the jobs there, and monitor their status.
Use case: Kueue provides the simplest Kubernetes-based batch job orchestration with resource quotas. In multi-tenant Kubernetes clusters, organizations often deploy mixed workloads - like ML training jobs, simulations, and large batch ETL pipelines - but they may want maximum native Kubernetes compatibility without introducing a new scheduler. Kueue stands out by working with the default Kubernetes scheduler rather than replacing it. Instead of scheduling pods directly, Kueue manages suspending, queuing, and admitting entire jobs via Kubernetes-native fields (spec.suspend), letting the default scheduler handle the pod placement once admitted.
Compared to Volcano (which uses a custom scheduler) and Apache YuniKorn (which fully replaces the Kubernetes scheduler), Kueue’s “job-first, pod-native” design allows clean, minimal, and incremental adoption. It is ideal for teams that cannot risk introducing a new scheduler binary into production clusters but still need advanced batch queuing behavior.
Here is the code snippet showing how Kueue manages suspend/resume and admission operations:
apiVersion: batch/v1
kind: Job
metadata:
name: etl-batch-job
labels:
kueue.x-k8s.io/queue-name: batch-queue
spec:
suspend: true # Kueue will unsuspend once resources are available
parallelism: 5
completions: 5
template:
spec:
containers:
- name: etl
image: busybox
command: ["sh", "-c", "echo Processing; sleep 30"]
restartPolicy: Never
---
apiVersion: kueue.x-k8s.io/v1beta1
kind: LocalQueue
metadata:
name: batch-queue
spec: {}
Feature comparison: Apache YuniKorn vs Volcanno.sh vs Kueue
The following table compares Apache YuniKorn, Volcano.sh, and Kueue across key features:
| Feature | Apache YuniKorn | Volcano.sh | Kueue |
| Batch Workload Support | ✅ | ✅ | ✅ |
| Gang Scheduling | ✅ | ✅ | ❌ |
| Fair Scheduling | ✅ | ✅ | ✅ |
| Resource Quotas | ✅ | ✅ | ✅ |
| Dependency Handling | ✅ | ✅ | ❌ |
| Multi-Tenancy Support | ✅ (Strong Support) | ⚠️ Limited | ❌ |
| Ease of Use | Moderate | Steeper Learning Curve | Easy |
| Integration with K8s | Standard APIs | Custom APIs/Annotations | Native Integration |
| Preemption Support | ✅ | ✅ | ✅ |
| Replaces Default Scheduler | ✅ | ❌ (Works alongside) | ❌ (Works alongside) |
| Scalability | High | High | Moderate |
Selecting the right batch processing tool
Choosing the right batch scheduling tool for Kubernetes depends on the specific requirements of your workloads and organization:
- Apache YuniKorn is ideal for environments requiring a universal scheduler that replaces Kubernetes’ default scheduler, offering excellent multi-tenancy and hierarchical fairness for both batch and service workloads.
- Volcano.sh shines in high-performance environments like AI/ML and deep learning, thanks to its advanced features like gang scheduling and job dependency management.
- Kueue is perfect for Kubernetes-native setups, providing robust job queueing, priority scheduling, and resource quotas.
By aligning these tools with your workload demands — be it fairness, scalability, or advanced scheduling policies — you can leverage Kubernetes at its full potential for batch processing.
Final words
In this blog, we explored and compared different tools for batch processing in Kubernetes — YuniKorn, Volcano, and Kueue. Each has its strengths. While these tools can significantly streamline batch processing, implementing them effectively can sometimes be challenging.
If you’re unsure which tool best fits your environment or need help setting things up, please reach out to our Kubernetes experts. We’re here to help you get the most out of your batch processing setup. To have a discussion about this blog post or to ask any questions, please find me on LinkedIn.
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like







