Deploying AI Models to Production in the Cloud

The journey from a working AI model in a notebook to a reliable, scalable production service represents one of the most significant challenges in the machine learning lifecycle. This critical transition requires not just technical knowledge but strategic decision-making about deployment architecture, performance requirements, and operational considerations.
Cloud platforms have emerged as the preferred environment for AI model deployment, offering unparalleled flexibility, scalability, and specialized infrastructure for ML workloads. The business impact is substantial: faster time-to-market, reduced operational overhead, and the ability to leverage cutting-edge hardware without capital investment.
Unlike traditional software, AI models, especially deep learning and large language models, introduce unique deployment challenges:
- Model Versioning: Ensuring consistency and traceability across environments while enabling controlled updates
- Performance Monitoring: Implementing comprehensive technical and business metrics to detect performance degradation early
- Operational Complexity: Managing sophisticated infrastructure requirements while minimizing maintenance overhead
This article provides a systematic exploration of cloud deployment strategies for AI models, balancing performance, cost, and operational demands. Whether you’re deploying your first model or optimizing an existing ML platform, you’ll find actionable insights based on industry best practices.
Model preparation for deployment
Before exploring specific deployment architectures, we must bridge the gap between model training and production environments through proper preparation techniques.
Converting models to deployment-ready formats
Training frameworks prioritize flexibility and experimentation, but for production, models need to be efficient, portable, and easy to load.
Key tasks:
- Convert the model to a standard format suitable for production inference.
- Ensure compatibility with the chosen serving environment (e.g., TensorFlow Serving, TorchServe, or Triton).
- Validate that the model supports batch size, input/output names, and dynamic axes.
Supported formats:
- ONNX: A framework-neutral format for cross-platform deployment.
- TensorFlow SavedModel: Optimized for TensorFlow Serving.
- TorchScript: Converts PyTorch models for fast loading in production.
This PyTorch-to-ONNX conversion example demonstrates the process:
# Example: Converting a PyTorch model to ONNX
import torch
import torchvision
# Load a pretrained model
model = torchvision.models.resnet50(pretrained=True)
model.eval()
# Create dummy input tensor
dummy_input = torch.randn(1, 3, 224, 224)
# Export to ONNX
torch.onnx.export(
model, # model being run
dummy_input, # model input
"resnet50.onnx", # output file
export_params=True, # store the trained parameter weights
opset_version=13, # the ONNX version to export the model to
do_constant_folding=True, # optimization
input_names=['input'], # the model's input names
output_names=['output'], # the model's output names
dynamic_axes={'input': {0: 'batch_size'}, # variable length axes
'output': {0: 'batch_size'}}
)
Optimization techniques for inference
Optimizations reduce compute needs without hurting accuracy. These steps speed up inference, especially on resource-limited hardware.
- Quantization: Converting floating-point weights to lower-precision formats (INT8, FP16) reduces memory footprint and often improves throughput on specialized hardware
- Pruning: Removing unnecessary connections in neural networks to decrease model size
- Knowledge Distillation: Creating smaller models that replicate the behavior of larger ones
For more details, see Model Optimization for Inference.
Resource planning considerations
Each model has different needs. Some rely on CPUs, others on GPUs. Choosing the right setup avoids overprovisioning and slow response times.
Think of it like this:
If you’re building a chatbot, users expect instant replies—real-time inference on a GPU is ideal. But if you’re analyzing historical data, batch processing on CPUs is more cost-effective.
When planning deployment, consider:
- Compute needs and memory usage
- Latency vs. throughput requirements
- Traffic patterns, including spikes and long-term growth
To manage resources efficiently, use multi-instance GPUs, adjust deployments based on demand, and optimize networking for distributed workloads.
Profiling tools like NVIDIA Nsight, TensorFlow Profiler, and PyTorch Profiler help uncover bottlenecks before rollout.
Batch vs. real-time inference requirements
Real-time systems need low-latency setups. Batch systems need high throughput.
Real-time systems— like recommendation engines or chat features—must respond in milliseconds. These setups benefit from GPU-backed servers and low-latency infrastructure.
Batch systems, such as overnight credit scoring or trend analysis, prioritize processing large volumes over time and can run on CPUs or spot instances.
When selecting your approach, match your compute resources, autoscaling, and caching strategies to the application’s response time needs and traffic patterns. This ensures both performance and cost-efficiency.
Model serving frameworks
With models prepared for deployment, we need infrastructure to make them available for inference requests. Model serving frameworks provide the foundation for reliable, scalable model delivery in production environments.
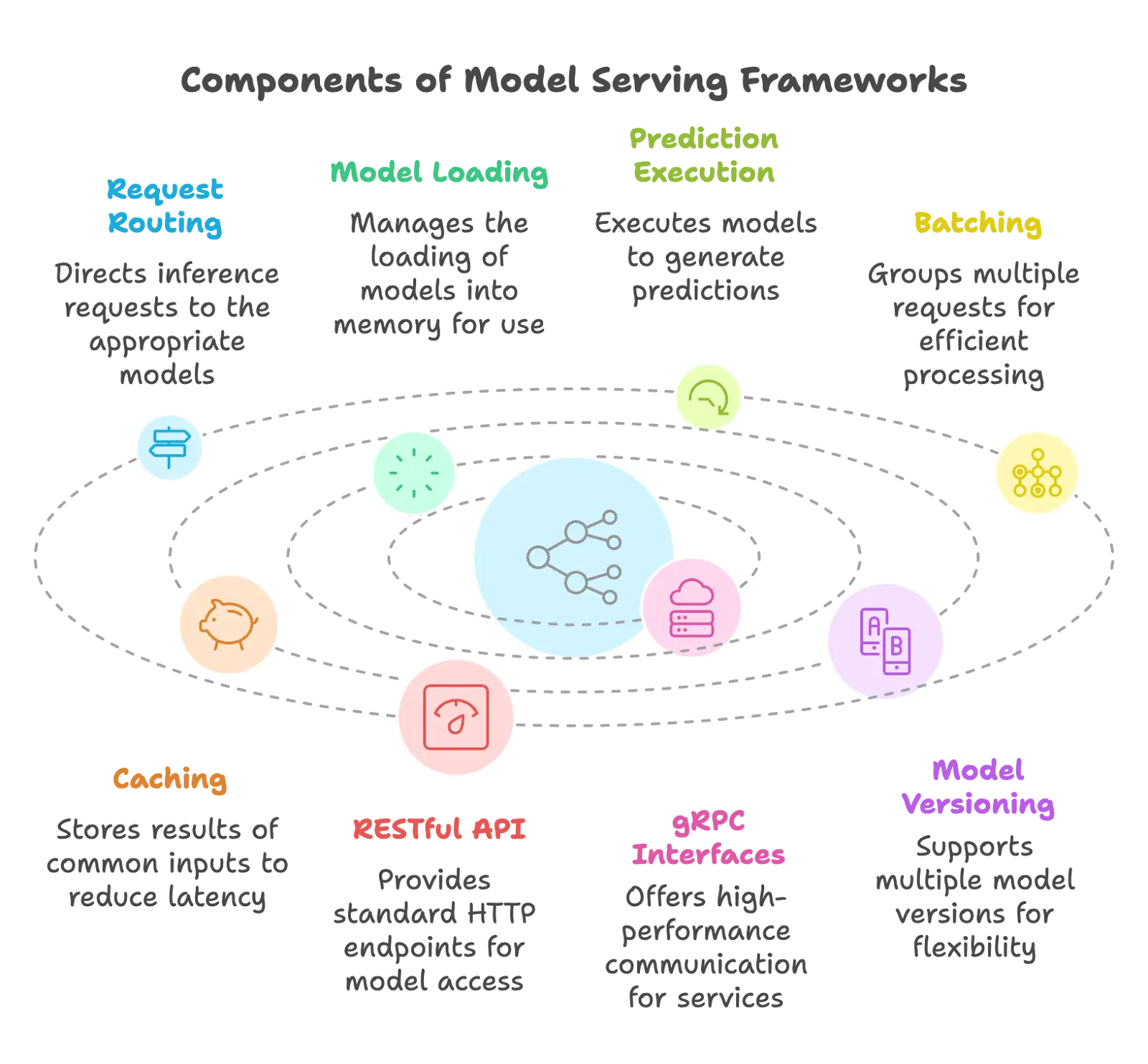
The diagram illustrates the core components of model serving frameworks, showing how they work together to support ML models in production. Request routing, model loading, prediction execution, batching, caching, API interfaces, and versioning create an integrated system that efficiently handles inference requests while maintaining operational flexibility.
Understanding serving frameworks
Training a model is only half the job—serving frameworks make that model available for real-world use. Without them, managing requests, scaling, and model updates would require custom infrastructure.
Why serving frameworks are essential:
- Handle concurrent requests without writing manual load-balancing logic
- Manage model lifecycle, including versioning and smooth rollouts
- Optimize performance with features like request batching and GPU acceleration
- Expose standard APIs (REST/gRPC) to integrate easily with applications
They act as the “glue” between your ML models and production systems, letting engineers focus on building features instead of managing servers.
Popular frameworks like TensorFlow Serving, TorchServe, NVIDIA Triton, and newer LLM-serving tools (like TGI and vLLM) are all designed to do this, but the core purpose remains the same: serving models efficiently and reliably at scale. See deployment charts for practical implementations.
Bridging models to production
Serving frameworks help transition from a local .pt or .pb file to a live, queryable service. Here’s a simplified example showing how a PyTorch model might be served with FastAPI:
# Example: Serving a PyTorch model with FastAPI
from fastapi import FastAPI, Request
import torch
import torchvision.transforms as T
from PIL import Image
import io
model = torch.hub.load('pytorch/vision', 'resnet18', pretrained=True)
model.eval()
transform = T.Compose([T.Resize(256), T.CenterCrop(224), T.ToTensor()])
app = FastAPI()
@app.post("/predict")
async def predict(request: Request):
data = await request.body()
image = Image.open(io.BytesIO(data))
input_tensor = transform(image).unsqueeze(0)
with torch.no_grad():
output = model(input_tensor)
return {"prediction": output.argmax().item()}
This is what serving looks like at the application level: load a model, accept inputs, and return predictions, all wrapped in an API.
Production-grade frameworks abstract these steps and add more control over versioning, scaling, and monitoring, making them essential at scale.
API interfaces and lifecycle management
Most serving frameworks expose standardized interfaces:
- REST APIs: HTTP-based interfaces with JSON payloads, offering broad compatibility
- gRPC: High-performance RPC framework using Protocol Buffers, ideal for internal services with high throughput requirements
To support reliable operations, serving frameworks also offer lifecycle features like:
- Model Versioning: Controlling which versions are active and available
- Shadow Deployments: Testing new models with production traffic without affecting user-facing results
- Progressive Rollouts: Gradually increasing traffic to new model versions
Cloud deployment architectures
With an understanding of model preparation and serving frameworks, we can explore architectural patterns for deploying ML models in the cloud. Each approach offers different tradeoffs in performance, flexibility, and operational complexity.
Containerization strategy
Containerization involves packaging your model, its runtime, and all dependencies into a portable container image. Tools like Docker make this easy and repeatable across environments. This approach works well when you need tight control over dependencies, consistent performance, and seamless deployment to orchestration platforms like Kubernetes. Some key advantages include portability across cloud providers, smooth rollback and versioning, and compatibility with CI/CD pipelines and monitoring tools.
A typical container-based ML stack includes:
- Docker for building and packaging the model
- Kubernetes for orchestration, scaling, and fault tolerance
- Serving frameworks like TensorFlow Serving, TorchServe, or a custom FastAPI app
- Kubernetes features such as Deployments, Services, Horizontal Pod Autoscalers (HPA), and GPU scheduling
For more advanced use cases, tools like KServe extend Kubernetes with ML-specific functionality and integrate well with the Kubeflow ecosystem to manage the full ML lifecycle.
Serverless deployment
Serverless (or Function-as-a-Service, FaaS) lets you run models without managing servers. You deploy small functions that the cloud provider runs on demand. Examples include AWS Lambda, Azure Functions, and Google Cloud Functions. This approach works best when inference is infrequent, unpredictable, or when you want to avoid idle costs. It’s ideal for lightweight models or preprocessing tasks where you don’t need a persistent service running.
Conceptually, it works like this:
A user request triggers a function. The function loads the model, runs inference, and returns a response. After execution, the function shuts down—unless it’s provisioned to stay warm.
There are some challenges to consider.
Cold start latency can affect performance, especially with larger models. Memory and execution time are limited. GPU support is still evolving but improving with newer options like Lambda GPU or serverless containers.
To make serverless more effective for ML:
- Use provisioned concurrency to reduce cold starts
- Compress models for faster loading
- Choose runtimes optimized for quick startup
Serverless shines in bursty or cost-sensitive scenarios, but heavier workloads may benefit more from containers or managed services.
Cloud provider ML platforms
Managed platforms from cloud providers abstract the infrastructure behind ML deployment. They offer built-in pipelines, scaling, monitoring, and APIs. Examples include:
- AWS SageMaker: End-to-end platform with deployment options ranging from real-time endpoints to batch jobs
- Google Vertex AI: Integrated platform with AutoML capabilities and custom model deployment
- Azure ML: Enterprise-focused service with strong Microsoft ecosystem integration
These platforms work well when you want to move fast with minimal DevOps, run batch jobs or AutoML workflows, or are already invested in that cloud ecosystem. However, they come with tradeoffs. You get less control over low-level infrastructure, and workflows can be opinionated or rigid. Cost visibility may also be limited unless actively monitored.
To optimize costs on these platforms:
- Use auto-scaling to match traffic patterns
- Choose right-sized instance types
- Run non-critical workloads on spot instances
- Enable asynchronous inference when real-time responses aren’t required
Cloud ML platforms are ideal for teams looking to accelerate deployment with managed services, but it’s important to balance ease of use with long-term control and visibility.
Edge and hybrid deployments
While cloud deployments offer scalability and managed services, some scenarios require computation closer to data sources. Edge and hybrid approaches address latency, bandwidth, and privacy challenges.
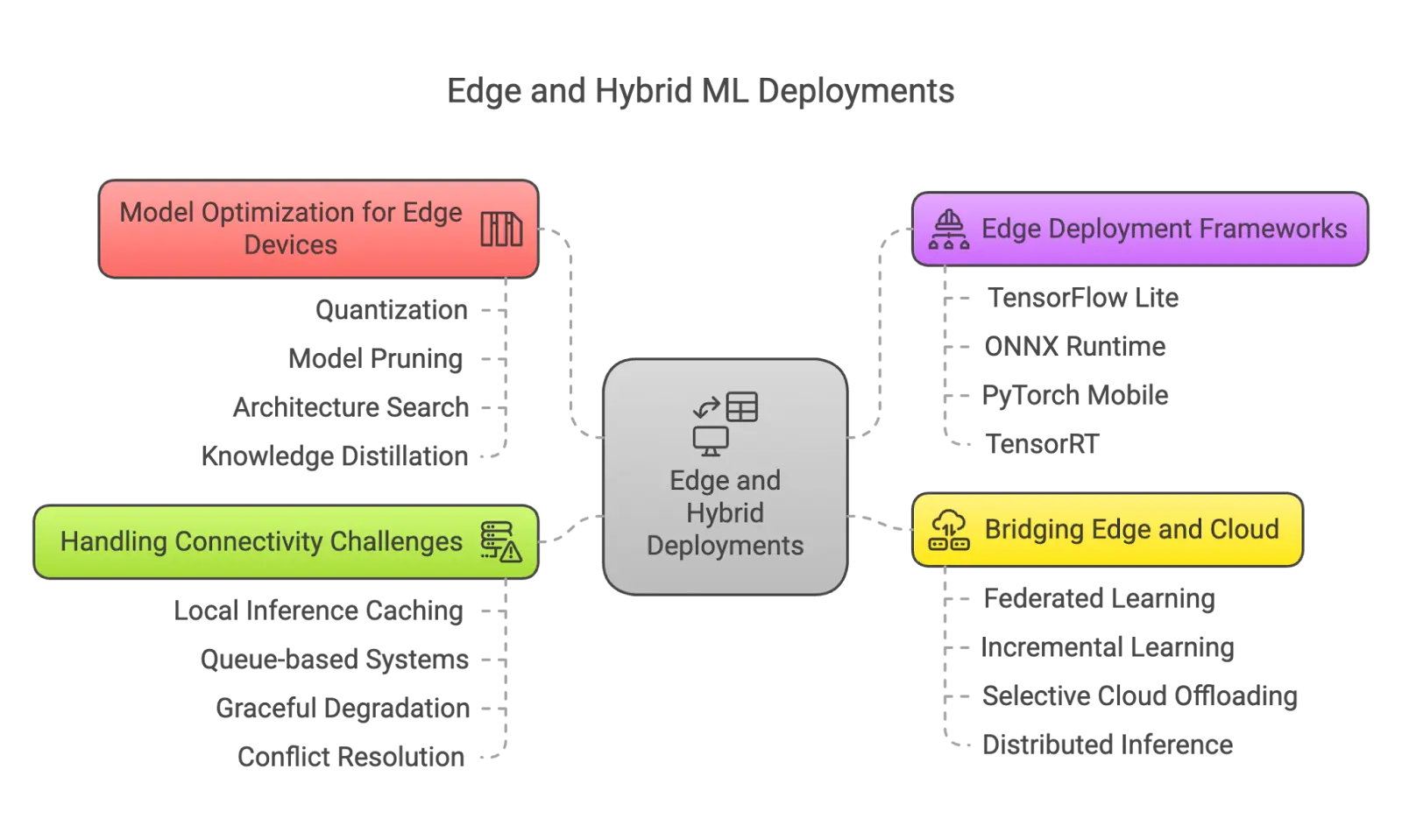
Model optimization for edge devices
Not all inference needs to happen in the cloud. In many cases, like wearables, IoT sensors, or factory equipment, running models on edge devices reduces latency, ensures quick responses, and avoids reliance on connectivity.
Edge devices often have constrained resources, requiring specialized optimization:
- Quantization: Essential for reducing model size and computational requirements
- Pruning: Removing redundant weights to decrease the memory footprint
- Architecture Selection: Using efficient network architectures designed for edge deployment
Frameworks like TensorFlow Lite, ONNX Runtime, and PyTorch Mobile provide optimized environments for edge deployment with minimal overhead.
Bridging edge and cloud
Some use cases benefit from both edge and cloud, this is where hybrid architectures work well. They combine edge inference for speed and privacy with cloud infrastructure for heavy workloads and coordination.
A hybrid setup is ideal when your device must respond instantly, but also needs to sync periodically with the cloud for updates or deeper analysis. It’s especially useful when dealing with privacy-sensitive data that can’t be transmitted but needs centralized learning or monitoring.
Here’s how it typically works:
Time-critical or private tasks run locally on the device, while complex processing is offloaded to the cloud when possible. In some cases, federated learning is used, where models train on the device and only share updates with a central server.
Hybrid deployments must also handle unreliable or limited connectivity. Devices should be able to cache results locally, queue updates for later, and degrade gracefully so basic functions continue even when the cloud is unreachable.
This setup offers the best of both worlds: low-latency decision-making close to the data source and centralized control and scalability in the cloud.
Production operations
Deploying a model is just the beginning of its lifecycle. Production ML systems require sophisticated operational practices to ensure reliability, performance, and continued accuracy.
CI/CD for ML model deployment
ML-specific CI/CD extends traditional software pipelines with:
- Model validation against quality thresholds
- Performance testing for latency and throughput
- A/B testing configurations for controlled rollouts
- Dataset verification to prevent training-serving skew
# Example GitHub Actions workflow for ML model deployment
name: Model Deployment Pipeline
on:
push:
branches: [main]
paths:
- 'models/**'
jobs:
test_and_deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.9'
- name: Install dependencies
run: pip install -r requirements.txt
- name: Run model validation tests
run: pytest tests/model_validation/
- name: Check performance metrics
run: python scripts/benchmark_model.py
- name: Deploy to staging
run: python scripts/deploy_model.py --environment=staging
- name: Run integration tests
run: pytest tests/integration/
- name: Deploy to production
if: success()
run: python scripts/deploy_model.py --environment=production
GitOps approaches using tools like ArgoCD or Flux provide declarative management of ML deployments across environments.
Progressive deployment and monitoring
Production ML requires careful rollout strategies:
- Canary Deployments: Outing a small percentage of traffic to new model versions
- A/B Testing: Comparing metrics between model versions to make data-driven decisions about which performs better
- Shadow Mode: Running new models alongside production without affecting outputs
ML systems require monitoring beyond traditional application metrics. Key monitoring areas include:
- Distribution Tracking: Detecting shifts in prediction patterns that may indicate drift
- Feature Statistics: Identifying data quality issues before they impact performance
- Business Metrics: Connecting model behavior to business outcomes
Automated drift detection systems compare production data distributions with training data, providing early warning of potential issues..
Security and scaling strategies
ML systems present unique security challenges that must be addressed in production deployments:
- Model Security: Protecting against extraction attacks and adversarial examples
- Data Privacy: Safeguarding training data and user inputs
- Explainability: Meeting regulatory requirements for model transparency
Scaling approaches must match workload characteristics:
- Horizontal Scaling: Adding prediction servers for stateless models
- Vertical Scaling: Increasing resources for memory-intensive models
- Predictive Scaling: Adjusting capacity based on anticipated demand
Conclusion: choosing the right approach
Selecting the right ML deployment architecture is about finding the right balance. Teams must weigh performance needs—like latency, throughput, and resource efficiency—against operational complexity, cost constraints, and long-term flexibility. Sometimes, the internal team is not trained enough to manage the complexities that arise while deploying AI models. Let us handle the operational aspects, such as building and managing AI infrastructure, and you can focus on adding value to your customers.
The landscape is evolving quickly, with MLOps platforms, hardware accelerators, and edge-cloud patterns reshaping what’s possible. Success often begins with approaches that match current capabilities. From there, teams can refine their setup through incremental improvements based on real-world challenges.
It’s also important to stay open to new technologies and trends as they mature. By understanding the tradeoffs between deployment architectures, teams can build systems that not only work today but also scale and adapt tomorrow. The right approach is rarely fixed—it grows with your needs, enabling sustainable ML infrastructure that delivers consistent business value.
I hope you found this guide insightful. If you’d like to discuss AI Models and Kubernetes further, feel free to connect with me on LinkedIn.
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like