
Exploring AI Model Inference: Servers, Frameworks, and Optimization Strategies

Over the past two years, we’ve witnessed the rise of Large Language Models (LLM) and Multimodal models distributed as Software as a Service (SaaS) applications like ChatGPT, Claude, Sora, among others. These SaaS applications demonstrate the tangible benefits AI models offer in an accessible format. However, integrating AI into your business poses challenges when relying on such SaaS applications, primarily due to the lack of control over data storage. Plus, you might need to fine-tune them with your proprietary data to make it more contextual. This entire process of developing/fine-tuning the models and then deploying them in production is quite complex and this is where MLOps as a practice comes in. Now, one critical part of the MLOps process is Inference, i.e., when models are deployed in production so they can be used to solve business problems.
Inference refers to using a trained machine learning model to make predictions or decisions based on new input data. It is a crucial part of the machine learning workflow, as it allows the model to be utilized in real-world applications to perform tasks such as image recognition, natural language processing, recommendation systems, and many others.
In this blog post, we aim to underscore the crucial decisions that must be taken into account when considering deploying a model on your infrastructure. We’ll delve into topics such as exploring various deployment options for trained models, identifying optimizations to minimize infrastructure needs for hosting the models, and evaluating inference servers and frameworks to streamline operational aspects of deploying models in production. Making informed decisions in these areas empowers you to effectively select the optimal path or approach for managing model deployment in production.
Model serving modes
Typically, models integrate into AI enabled applications or products – accepting input and producing predictions as output. Depending on the specific use case or product design, there are generally three model serving options available:
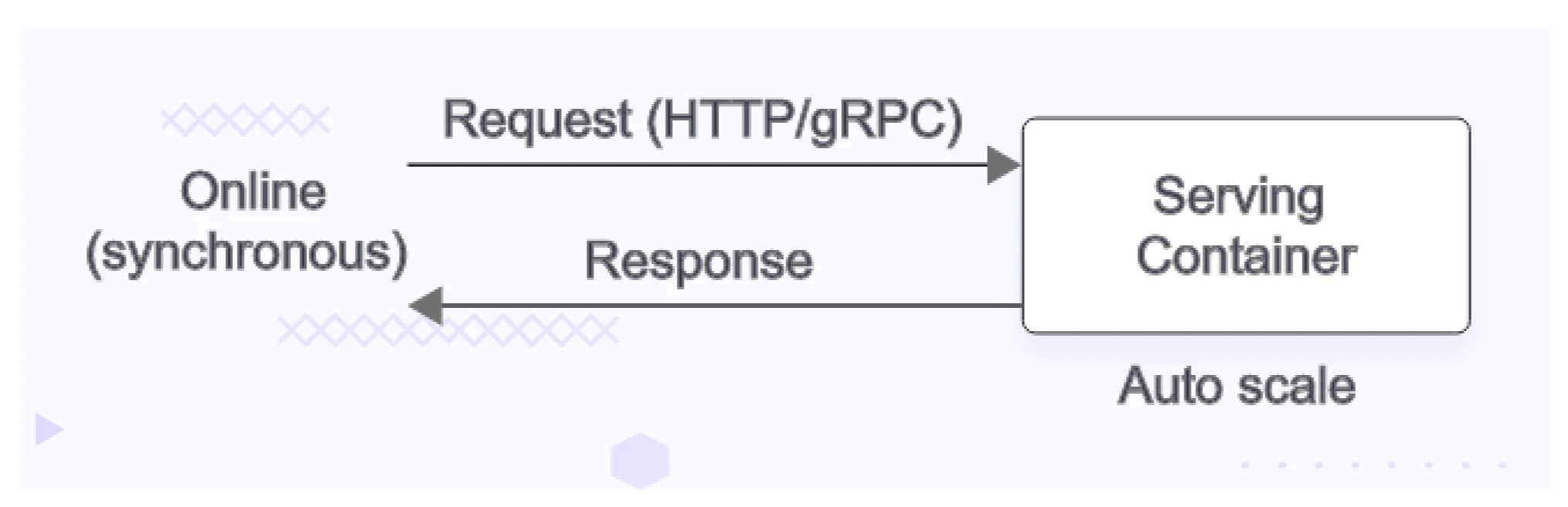
Online serving
- This resembles a REST API endpoint, where input is provided to the model via the endpoint, and immediate predictions are returned as output. It operates synchronously.
- This is a slightly costly approach as it requires you to handle multiple user requests in parallel. Inference servers usually run multiple copies of the model across the available GPU or AI GPU cloud to handle this.
- From an infrastructure standpoint, you will need the options to scale in or scale out based on the surge or decline in user requests.
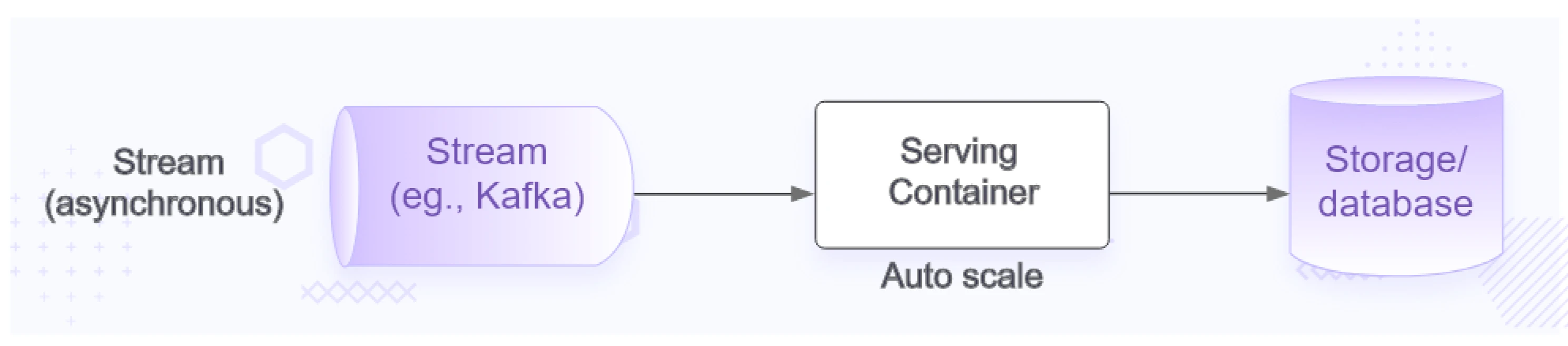
Streaming Serving
- Some application architectures follow asynchronous design principles. Here, services rely on a shared message bus (such as Kafka or SQS) to receive signals for processing new data. In streaming deployment, the model can receive input data from the message bus and deliver predictions either back to the message bus or to storage servers.
- This is a slightly flexible model of deployment, as in asynchronous systems, you do not have any hard coupling between the systems. You can leverage different model options here and have parallel consumers to validate the performance.
- The scaling principle remains same as the other options.
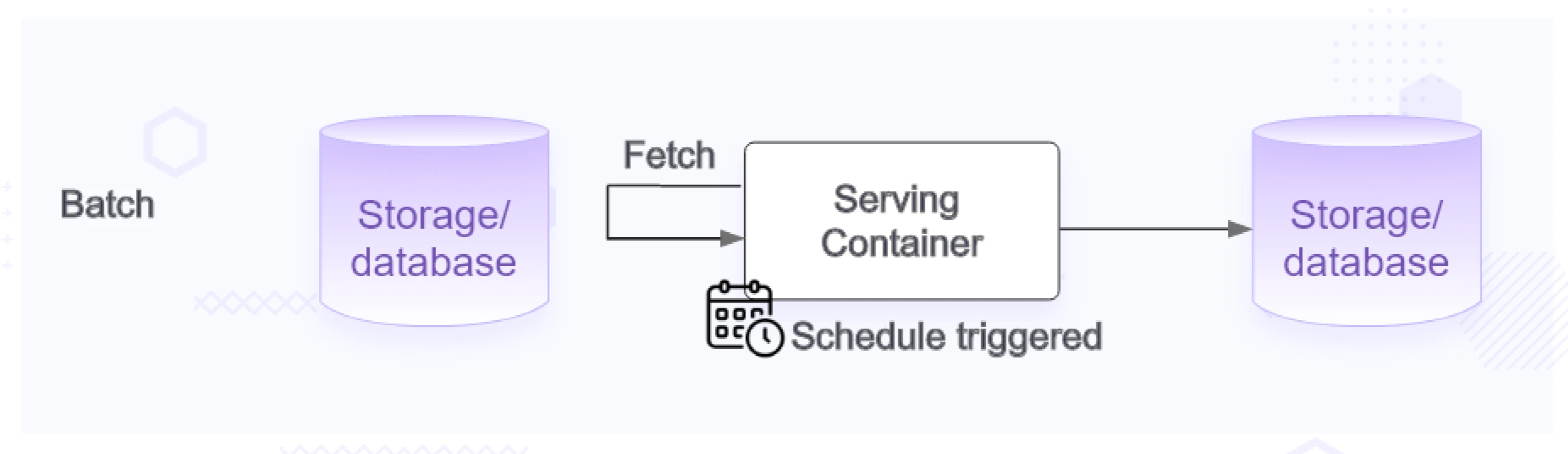
Batch serving
- With this option, a model is deployed as part of a batch pipeline. Input datasets are prepared beforehand, and the model generates predictions, storing them in a storage server for later use by the product in enabling specific features.
- This is more predictive model of deployment and you can manage the infra upfront based on the scale estimates. Instead of predicting for every request, the model predicts on a batch of data in one request.
| Serving Modes | Description | Pros | Cons |
|---|---|---|---|
| Online | - Resembles a REST API endpoint - Operates synchronously - Handles multiple user requests in parallel | - Low latency predictions - Elastic scaling based on demand | - Expensive to handle high request volumes - Complex parallel request handling |
| Streaming | - Receives input data from a message bus (e.g., Kafka or SQS) - Delivers predictions back to the message bus or storage servers - Asynchronous design | - Loosely coupled architecture - Supports parallel model evaluation - Asynchronous processing | - Similar scalability challenges as online deployment |
| Batch | - Model deployed as part of a batch pipeline - Input datasets prepared beforehand - Predictions stored in storage servers | - Predictable resource requirements - Efficient for bulk processing | - High latency predictions - Separate request handling for real-time use cases |
Inference servers
An inference server works by receiving input data, typically in the form of requests from clients, which can include queries, images, text, or other forms of data. It then processes this data through trained machine learning models or algorithms to generate predictions, classifications, or other outputs.
When used in a production environment, it needs to be highly scalable to process large volumes of user requests with low latency and should optimize model execution for speed, memory usage, and energy efficiency. Apart from performance metrics, teams usually spend quite a bit of time on operational aspects i.e. managing the model deployments and enabling customizations like adding business logic or preprocessing steps into the inference pipeline.
The landscape of AI hardware is rapidly evolving, with much of the optimization in inference relying on effectively harnessing new hardware accelerators for GPU networking, storage access, and more. As a result, a plethora of inference servers are currently available, with many new ones emerging. In this discussion, we categorize the existing offerings into two broad categories and explore the value they provide.
- Native ML/DL servers
- Specialized inference servers
What are native ML/DL servers?
To build a Machine Learning (ML) / Deep Learning (DL) model, we usually use AI frameworks/libraries like PyTorch, TensorFlow, etc. This category includes inference servers built by the same frameworks to serve the trained models like TorchServe for PyTorch, TensorServing for Tensorflow models, etc. Their sole purpose is to serve the models trained using the same framework. They provide most of the required capabilities like batch inferencing, optimization support, and service endpoints.
Advantages of native ML/DL servers:
- Broad hardware support (CPUs, GPUs, TPUs)
- Can be used for both training and inference
- Seamless integration with the native ML/DL frameworks
- Large ecosystem and community support
Disadvantages of native ML/DL servers:
- Not optimized specifically for inference workloads
- May have higher latency and lower throughput compared to specialized servers
- Can be more resource-intensive and costly for inference workloads
- May require more manual effort for optimizations and deployment management
What are specialized inference servers?
Specialized inference servers are purpose-built inference servers to provide the best optimization possible. On the hardware side, we have certain inference servers from all the major GPU vendors, i.e. Nvidia, Intel, and AMD. They have their inference engine or frameworks that use kernel drivers, libraries, and compilers to provide the best optimization possible. They use different compilers and optimization techniques to reduce the latency and memory consumption. Some of the popular inference servers from known vendors include:
Optimized for Nvidia GPUs, provides high-performance inference for deep learning models, supports models from various frameworks, and enables easy deployment and management of inference workloads.
Enables optimized inference across Intel hardware (CPUs, GPUs, VPUs), supports models from various frameworks, and provides tools for optimizing and deploying deep learning models on Intel architecture.
Optimized for AMD GPUs and other AMD accelerators, provides optimized deep learning inference performance on AMD hardware, supports models from various frameworks, and integrates with the ROCm software stack.
Certain large and complex AI models, particularly large language models (LLMs), require specialized inference servers for several reasons:
- LLMs have a massive number of parameters, often in the billions, which translates to high computational and memory requirements during inference.
- Inference needs to be performed quickly, with low latency, to support real-time applications like chatbots, text generation, and question-answering.
- Deploying LLMs at scale requires high throughput and efficient resource utilization to serve numerous concurrent requests cost-effectively.
- General-purpose ML/DL inference servers may need to be optimized for the specific computational patterns and memory access patterns of LLMs, leading to suboptimal performance and efficiency.
Following are some of the inference servers that are for serving LLMs specifically:
Advantages of specialized inference servers:
- Optimized specifically for efficient inference workloads
- Lower latency and higher throughput for inference
- Often more cost-effective for inference deployments
- Leverage hardware-specific optimizations (e.g., Tensor Cores, INT8 support)
- Simplified deployment and management of inference workflows
- Often provide advanced features for inference workflows (e.g., batching, ensembling, model analytics)
- Can leverage optimized libraries and kernels for specific hardware (e.g., CUDA, ROCm)
Disadvantages of specialized inference servers:
- May have limited hardware support (e.g., only Nvidia GPUs, Intel CPUs/GPUs)
- Smaller ecosystem and community compared to native ML/DL frameworks
- May require additional tooling or integration efforts for model conversion/optimization
- Limited support for training workloads (inference-only)
- May have limited support for custom models or architectures outside the main frameworks
- Potential vendor lock-in or dependency on specific hardware/software stacks
MLOps frameworks with model serving
Serving a model constitutes just one facet of the overall product lifecycle. There are numerous operational tasks involved, including deployment planning, managing different model versions, efficient traffic routing, dynamic scaling based on workload, implementing security measures, and setting up gateways for effective tenant-based routing.
Aside from operational considerations, there are both preparatory and follow-up tasks related to model serving, such as ensuring model availability in registries, integrating with evaluation frameworks, publishing model metadata, and designing workflows for preprocessing and post-processing data inputs and outputs.
Your operational team may already be utilizing orchestrators like Kubernetes for serving microservices, and they may prefer to handle model serving similarly. They might also have established cost optimization practices, such as utilizing spot instances or scaling clusters during non-peak hours.
MLOps frameworks-based solutions address all the phases of model development and deployment and also provide sufficient flexibility to the teams to plug whatever they already have in place. They provide options to streamline work during model development, such as offering services to provision notebooks for data scientists and integrating with storage solutions to enhance efficiency for data engineers. Furthermore, they facilitate integration with ML/DL frameworks, enabling model training on clusters as well.
In summary, these MLOps solutions offer comprehensive end-to-end support for developing, deploying, and operating the model in production. If your team is sizable and aims to establish a robust process or practice for effective management right from the start, opting for one of these solutions is highly recommended. Moreover, they offer customization and integration options that extend beyond the confines of supported tools, allowing you the flexibility to incorporate specific tools tailored to your needs.
Inference pipelines
As the usage of AI models is becoming more common, we are seeing production inference pipelines becoming more complex. For instance, there are certain tasks like text processing for which you might end up using multiple models to generate the final output. You might start with a classification model, and based on the result, you pass input data to another model to process it appropriately. This requires designing a flow of activities that sometimes even includes processing the output from one stage to prepare it for the next stage.
Most of the MLOps frameworks covered above support designing the inference pipelines natively. They use the capabilities of orchestrators like Kubernetes to schedule and execute the different stages effectively. Using these frameworks also allows you to use different inference servers that are purpose-built for a specific set of work.
There are also advanced ML Inference design patterns based on these concepts, like Ensembles and Cascaded Inferences.
Ensembles
An ensemble inference pipeline is a type of inference workflow that combines the predictions or outputs of multiple machine learning models to produce a final result. They serve as a machine learning strategy that integrates multiple models, referred to as base estimators, during the prediction phase. By adopting ensemble models, one can address the technical complexities associated with constructing a singular estimator. This approach involves sending the same input data to an ensemble of models and then combining or aggregating the predictions from all the models to derive the final, most accurate prediction.

To understand how an ensemble inference pipeline can be used in the real world consider the following example scenario for credit risk assessment. Banks could use an ensemble pipeline consisting of a machine learning model for predicting credit scores, a rule-based system for identifying potentially fraudulent applications, and a deep learning model for analyzing unstructured data like applicant social media activity. The outputs from these models would be aggregated to arrive at a final credit risk assessment for loan approval decisions.
Cascaded inferences
The cascaded inference pattern involves a sequential arrangement where the output of one model serves as the input for another, forming a cascading pattern. This technique proves valuable in mitigating model biases or addressing incomplete data scenarios by leveraging an additional predictor to compensate for these shortcomings.
Imagine a scenario where a primary model exhibits a certain bias or struggles with incomplete data, potentially leading to inaccurate predictions. In such cases, employing the Cascaded Inference pattern allows for the integration of a secondary model. This secondary model utilizes the output of the primary model as its input, thereby refining the predictions further or compensating for the limitations of the primary model. By cascading models in this manner, the overall predictive accuracy can be improved, leading to more reliable outcomes, especially in situations where individual models may falter due to inherent biases or data limitations.

In real-world, a cascaded inference pipeline for a credit card fraud detection system could involve a machine learning model that analyzes transaction patterns to identify potentially fraudulent activities. Suspicious transactions are then passed to a deeper neural network model that examines associated data like customer profiles and purchase details. Finally, a rule-based system applies specific policies and regulations to make the ultimate fraud determination.
Model optimization for inference
Deploying large AI models can be challenging due to their substantial computational, storage, and memory demands, as well as the need to ensure low-latency response times. A key optimization strategy is model compression, which involves techniques that reduce the model’s size.
Smaller models can be loaded faster, leading to lower latency, and they require fewer resources for computation, storage, and memory. By compressing the model, deployment becomes more easy and efficient, enabling quicker inference while minimizing resource requirements.
Compressing a model’s size is beneficial for optimizing deployment, but the challenge lies in achieving effective size reduction while preserving good model performance. Consequently, there is often a trade-off to balance between maintaining the model’s accuracy, adhering to computational resource constraints, and meeting latency requirements.
Here, we talk about three techniques aimed at reducing model size:-
- Quantization
- Pruning
- Distillation
Quantization
Quantization minimizes the memory necessary for loading and training a model by decreasing the precision of its weights. It involves converting model parameters from 32-bit to 16-bit, 8-bit, or 4-bit precision. By quantizing the model weights from 32-bit full-precision to 16-bit or 8-bit precision, you can substantially reduce the memory requirement of a model with one billion parameters to only 2 GB, cutting it by 50%, or even down to just 1 GB, a 75% reduction, for loading. However, as this optimization is achieved by moving to lower precise data types there will be loss of precision. So, it is always best to benchmark the results of quantization based on your use case. In most cases, a drop in prediction accuracy by 1-2% is a good trade-off to achieve low inference time and a reduction in infrastructure cost.
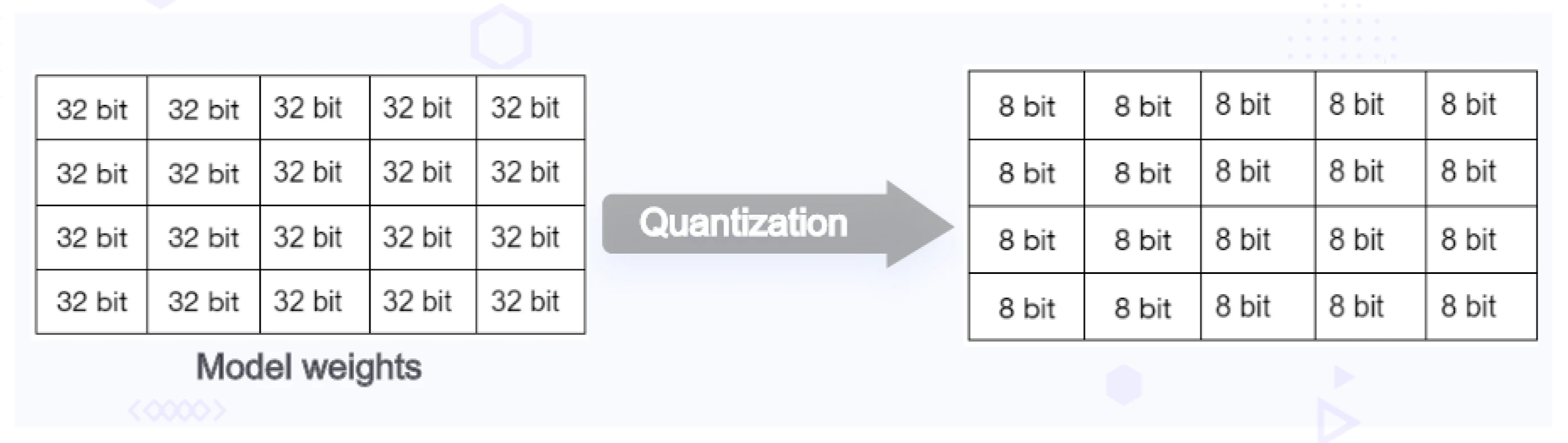
Quantization is broadly classified into two categories based on when you are applying it i.e post or pre-training.
Post training quantization (PTQ)
Post training quantization (PTQ) is a quantization technique that involves applying the quantization process to a trained model after it has finished training. This method entails converting the model’s weights and activations from high precision, like FP32, to lower precision, such as INT8.
While PTQ is relatively simple and easy to implement, it does not consider the effects of quantization during the training phase. Most of the inference servers support applying the PTQ to the trained models. Vendor specific frameworks provide supported libraries to enable it.
Quantization aware training (QAT)
Quantization-aware training (QAT) is an approach that considers the effects of quantization throughout the training process. During QAT, the model is trained using operations that simulate quantization, enabling it to adapt and perform effectively in a quantized representation. This method enhances accuracy by ensuring the model learns to accommodate quantization nuances, resulting in superior performance compared to post-training quantization.
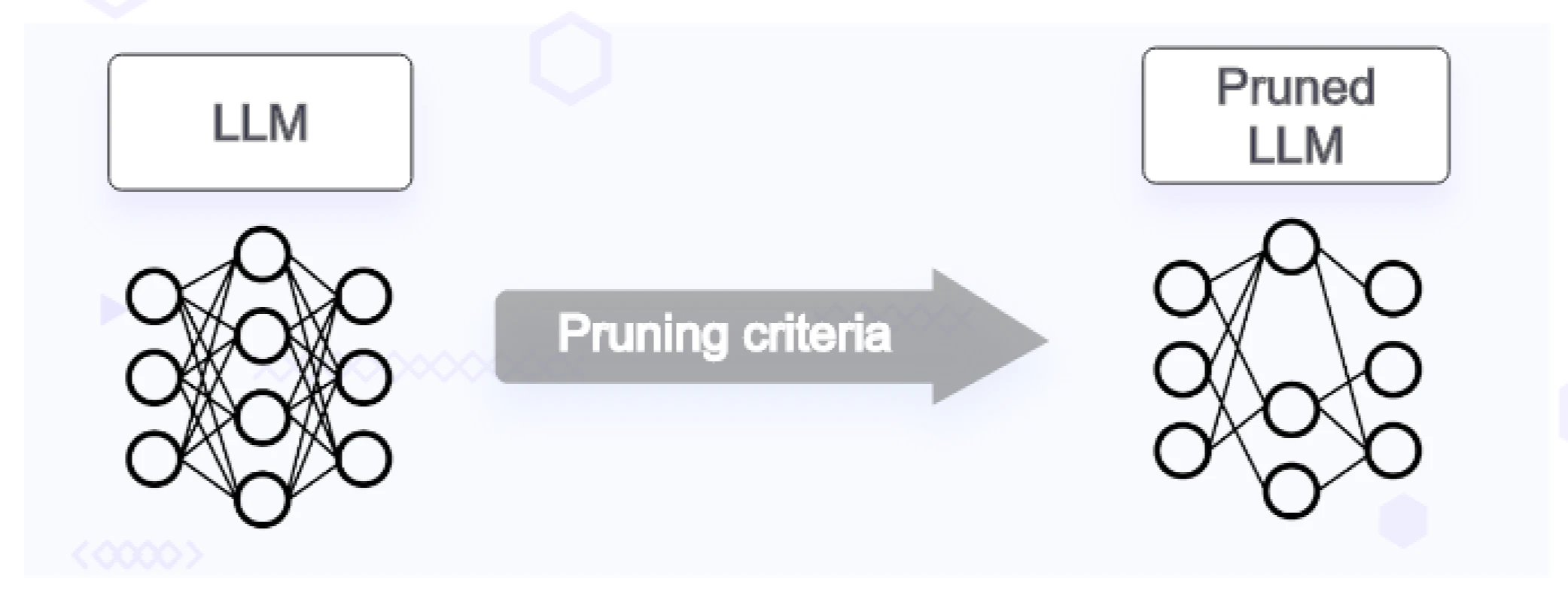
Pruning
Pruning endeavors to remove model weights that do not substantially contribute to the model’s overall performance. By discarding these weights, the model’s size for inference is reduced, consequently diminishing the necessary compute resources.
Pruning targets model weights that are either zero or extremely close to zero. There are post-training techniques, known as one-shot pruning methods, capable of eliminating weights without the need for retraining. However, one-shot pruning often presents a computational challenge, particularly for large models containing billions of parameters.
A post-training pruning technique, known as SparseGPT, seeks to address the difficulties associated with one-shot pruning for large language models. Designed specifically for language-based generative foundational models, SparseGPT introduces an algorithm capable of conducting sparse regression on a significant scale. Theoretically, pruning diminishes the size of the language model (LLM), thereby reducing computational requirements and model latency.
Distillation
Distillation is a method aimed at diminishing the size of a model, consequently cutting down on computations and enhancing model inference performance. It employs statistical techniques to train a compact student model based on a more extensive teacher model. The outcome is a student model that preserves a significant portion of the teacher’s model accuracy while employing fewer parameters. Once trained, the student model is utilized for inference tasks. Due to its reduced size, the student model demands less hardware, resulting in reduced costs per inference request.
| Optimization Method | Description | Pros | Cons |
|---|---|---|---|
| Quantization | Reduces the precision of model weights and activations from 32-bit to lower-bit representations (e.g., 8-bit, 4-bit) | - Significant reduction in model size - Faster inference with optimized low-precision operations | - Potential accuracy drop if not done carefully - Hardware support for low-precision operations required |
| Pruning | Removes redundant or less important weights from the model, resulting in a sparse model | - Can achieve high compression rates - Minimal or no accuracy loss when done properly | - Requires careful selection of pruning strategy and schedule - Sparse models may not fully utilize hardware acceleration |
| Distillation | Transfers knowledge from a large, accurate model (teacher) to a smaller model (student) | - Can significantly reduce model size without major accuracy loss - Student model can be optimized for target hardware | - Requires training a larger teacher model first - Additional computational cost for distillation process |
Conclusion
Inference servers serve as the backbone of AI applications, acting as the vital link between the trained AI model and real-world applications. This blog post tried to provide an overview of AI model inference servers, frameworks, and optimization strategies. It is essential to understand the various deployment options and considerations when considering deploying a model in your infrastructure. Although the list covered here is not exhaustive we tried to group options into categories so that it becomes logical to choose your next stack.
I hope you found this post informative and engaging. For more posts like this one, subscribe to our weekly newsletter. I’d love to hear your thoughts on this post, so do start a conversation on LinkedIn :)
References
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like








