
Introduction to NVIDIA Network Operator
 Sameer Kulkarni
Sameer Kulkarni  Bhavin Gandhi
Bhavin Gandhi Artificial intelligence (AI) and machine learning (ML) are transforming industries, from automotive to finance. Since the advent of using GPUs for AI/ML workloads in the last few years, processing large amounts of data has become significantly faster. Workload orchestrators like Kubernetes have also played an important role in maximizing GPU compute power.
However, one of the critical bottlenecks in this process is often the networking infrastructure. AI/ML training and inference workloads require the rapid and reliable transfer of massive datasets. Even the most powerful GPUs can be underutilized without an optimized networking setup, leading to significant delays and inefficiencies.
Kubernetes automates the deployment, scaling, and operation of application containers across clusters of hosts, providing a robust platform for running complex AI/ML workflows. However, while Kubernetes excels at managing compute resources, ensuring optimal networking remains a challenge that must be addressed to leverage its capabilities fully.
This is where network operators come into play. Network operators are specialized components that manage networking configurations and policies within a Kubernetes cluster. They streamline the deployment and management of network resources, ensuring consistent and reliable connectivity across the cluster.
In this blog post, we will explore NVIDIA Network Operator, understand how it works, identify its key features, and explain how it empowers you to unleash the full potential of your AI applications within the Kubernetes ecosystem.
What is the NVIDIA Network Operator?
The NVIDIA Network Operator brings super-fast networking capabilities to Kubernetes clusters. It is designed to address the unique networking needs of AI/ML workloads running on Kubernetes. It works with the NVIDIA GPU Operator to provide a comprehensive solution for deploying and managing GPU-accelerated AI/ML jobs. The NVIDIA Network Operator simplifies the configuration of advanced networking features, such as RDMA and GPUDirect, essential for high-performance AI/ML workloads.
Optimizing the network performance for AI/ML workloads on Kubernetes clusters requires configuring and managing several complex technologies:
-
Network drivers: Installing and maintaining drivers like OFED (Open Fabrics Enterprise Distribution) for high-performance networking. The OFED driver is provided by the OpenFabrics Alliance that includes drivers and libraries to enable high-performance networking. OFED supports various network protocols such as InfiniBand, RoCE, and iWARP, providing the necessary tools to leverage these technologies.
-
Device plugins: Deploying and configuring device plugins for RDMA (Remote Direct Memory Access) and SR-IOV (Single Root I/O Virtualization), which are crucial for efficient data transfer.
-
Container Network Interfaces (CNIs): Setting up secondary CNIs alongside the default Kubernetes CNI to manage specialized network configurations for your AI workloads.
-
IP address management (IPAM): Allocating and managing IP addresses for all the network components within the cluster.
-
Pod configurations: Configuring individual pods within the Kubernetes cluster to leverage the chosen CNIs, network devices, and other networking settings.
Configuring and maintaining all of the above manually is quite cumbersome and error-prone. In addition, it may also lead to an inability to reproduce the exact configuration, when needed.
The NVIDIA Network Operator addresses these challenges by providing:
-
Automation: Automates the deployment and configuration of network resources, streamlining the setup process and reducing manual effort.
-
Centralized management: Offers a single point of control for managing all network components, promoting consistency and simplifying troubleshooting.
-
Recommended defaults: The Network Operator Helm chart, enables easy installation of the operator itself along with all the components such as network drivers, CNIs, IPAM plugins, etc. It provides pre-configured default settings for all the components optimized for AI/ML workloads, reducing the need for extensive manual configuration. The defaults can be overridden easily using the chart’s values.yaml file, during installation.
-
Automated driver upgrades: Automates Mellanox OFED (MOFED) drive upgrades on the cluster nodes.
-
Node feature discovery: Node feature discovery (NFD) is a Kubernetes add-on for detecting hardware features such as CPU cores, memory, and GPUs on each node and advertising those features using node labels. Network Operator is bundled with NFD to automatically discover network devices on the nodes and label them accordingly.
Network Operator Custom Resources
Like any other Kubernetes Operator, NVIDIA Network Operator uses Custom Resources to extend Kubernetes API, defined using Custom Resource Definitions (CRDs). We will discuss two of the important CRDs for the Network Operator below.
NICClusterPolicy CRD
NICClusterPolicy defines the desired network configuration for your entire Kubernetes cluster and is the main configuration resource for the operator deployment. It is defined only once per cluster.
Here’s an example of the NICClusterPolicy custom resource. You can view the full CR as well as other CR examples in the Network Operator GitHub repository.
apiVersion: mellanox.com/v1alpha1
kind: NicClusterPolicy
metadata:
name: nic-cluster-policy
spec:
ofedDriver:
image: doca-driver
repository: nvcr.io/nvstaging/mellanox
version: 24.04-0.6.6.0-0
...
In the first section, the custom resource configures the Network Operator to run OFED driver with doca-driver image from Mellanox docker repository.
...
rdmaSharedDevicePlugin:
image: k8s-rdma-shared-dev-plugin
repository: ghcr.io/mellanox
version: 1.4.0
# The config below directly propagates to k8s-rdma-shared-device-plugin configuration.
# Replace 'devices' with your (RDMA capable) netdevice name.
config: |
{
"configList": [
{
"resourceName": "rdma_shared_device_a",
"rdmaHcaMax": 63,
"selectors": {
"vendors": ["15b3"],
"deviceIDs": ["101b"]
}
}
]
}
...
The second section configures the RDMA plugin using the k8s-rdma-shared-dev-plugin image. The config section directly propagates to the RDMA plugin configuration. It includes max RDMA resources specification and selectors for the RDMA-capable network device names.
The RDMA and SR-IOV plugins run as kubelet device plugins that support InfiniBand, RoCE and SR-IOV capabilities. It also supports Container Device Interface (CDI).
...
secondaryNetwork:
cniPlugins:
image: plugins
repository: ghcr.io/k8snetworkplumbingwg
version: v1.3.0
multus:
image: multus-cni
repository: ghcr.io/k8snetworkplumbingwg
version: v3.9.3
config: ''
ipamPlugin:
image: whereabouts
repository: ghcr.io/k8snetworkplumbingwg
version: v0.6.2
In the secondary network section, the CR configures a secondary CNI plugin from k8snetworkplumbingwg repository, a multus-cni and an IPAM plugin. The Multus CNI functions as a “meta-plugin”. It enables Kubernetes to use multiple CNI plugins simultaneously. The ipamPlugin helps the secondary CNIs with IP address management. We’ll learn more about secondary CNIs later in this blog post.
Since this CRD governs many important aspects of the operator, the operator Helm chart allows you to configure/override the NICClusterPolicy CR attributes during installation. Here are additional details of important attributes of the same.
| Attribute | Description |
|---|---|
| ofedDriver | Defines the configuration for deploying and managing the OFED driver. OFED is a crucial to enable features like RDMA (Remote Direct Memory Access). Defines the desired OFED version, installation method, etc. |
| rdmaSharedDevicePlugin & sriovDevicePlugin | Define how to deploy and configure device plugins for RDMA and SR-IOV functionalities. RDMA rdmaSharedDevicePlugin allows applications to directly access each other’s memory for faster data transfer. SR-IOV enables a & sriovDevicePlugin single physical network interface card (NIC) to appear as multiple virtual NICS for virtualized environments (like VMs). |
| ibKubernetes | This section is specifically relevant for deploying a network within an InfiniBand fabric. InfiniBand is a high-performance networking technology commonly used in data centers. If you’re utilizing an InfiniBand fabric, the NICClusterPolicy can define configurations specific to this technology within the ibKubernetes section. |
| secondaryNetwork | It allows you to configure secondary CNIs alongside the default Kubernetes CNI. Typically, the primary CNI is used for kubernetes cluster communication. A secondary network with RDMA/SR-IOV capabilities is used for high-performance AI/ML workloads. |
| nvlpam | This defines the configuration for the NVIDIA Kubernetes IP Address Management (IPAM) plugin. IPAM is responsible for allocating and managing IP addresses for all network components within the cluster. IPAM plugins ensure proper IP address management for the high-performance network environment. |
Network CRDs
While NICClusterPolicy takes care of a big chunk of the network configuration, you still need to define the secondary network using what’s called “Network CRDs”. The secondary network definition helps Kubernetes identify crucial pieces of information to work with it correctly. It helps to identify the type of the network, whether it is Host Device Network (HDN), Mac VLAN Network, or IP over InfiniBand Network (IPoIB). Depending on the type of the network, the network CRD defined would be either HostDeviceNetwork CRD, MacvlanNetwork CRD, or IPoIBNetwork CRD.
Here’s an example of a MacvlanNetwork CRD configured with whereabouts IPAM CNI.
apiVersion: mellanox.com/v1alpha1
kind: MacvlanNetwork
metadata:
name: rdma-net-ipam
spec:
networkNamespace: "default"
master: "ens2f0"
mode: "bridge"
mtu: 9000
ipam: |
{
"type": "whereabouts",
"datastore": "kubernetes",
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/whereabouts.d/whereabouts.kubeconfig"
},
"range": "192.168.2.225/28",
"exclude": [
"192.168.2.229/30",
"192.168.2.236/32"
],
"log_file" : "/var/log/whereabouts.log",
"log_level" : "info",
"gateway": "192.168.2.1"
}
Secondary Networks and CNIs
In Kubernetes, the default Container Network Interface (CNI) plugin provides basic networking functionality for pods within the cluster. However, for running complex AI/ML workloads, the capabilities of the default CNI might be insufficient. This is where secondary networks come into play.
Secondary networks are essentially additional network configurations alongside the default CNI. They are often established by deploying a separate CNI plugin, offering functionalities beyond the default one. This allows you to create specialized network environments tailored to the specific needs of your applications.
Specifically for AI/ML workloads the secondary networks help you communicate faster and more efficiently with the storage layer as well as other GPUs in the same or remote machines. They help you integrate with the latest networking technologies such as RDMA, RoCE, SR-IOV, GPUDirect over RDMA, etc. All these technologies enable the network to keep up with the super-fast data needs of the GPUs of today.
When it comes to installing and using a secondary network on Kubernetes clusters, there are specific CNIs that cater to making specific networking technologies available to the cluster, such as RDMA, SR-IOV, IPoIB, etc. Other than these, there are two particularly important CNIs of note that play a special role in enabling the secondary networks on the Kubernetes cluster.
1. Multus CNI
Multus CNI is a meta-plugin, a CNI plugin that can call multiple other CNI plugins. Unlike a traditional CNI plugin directly managing network interfaces, Multus acts as an intermediary, orchestrating the deployment and configuration of other CNI plugins.
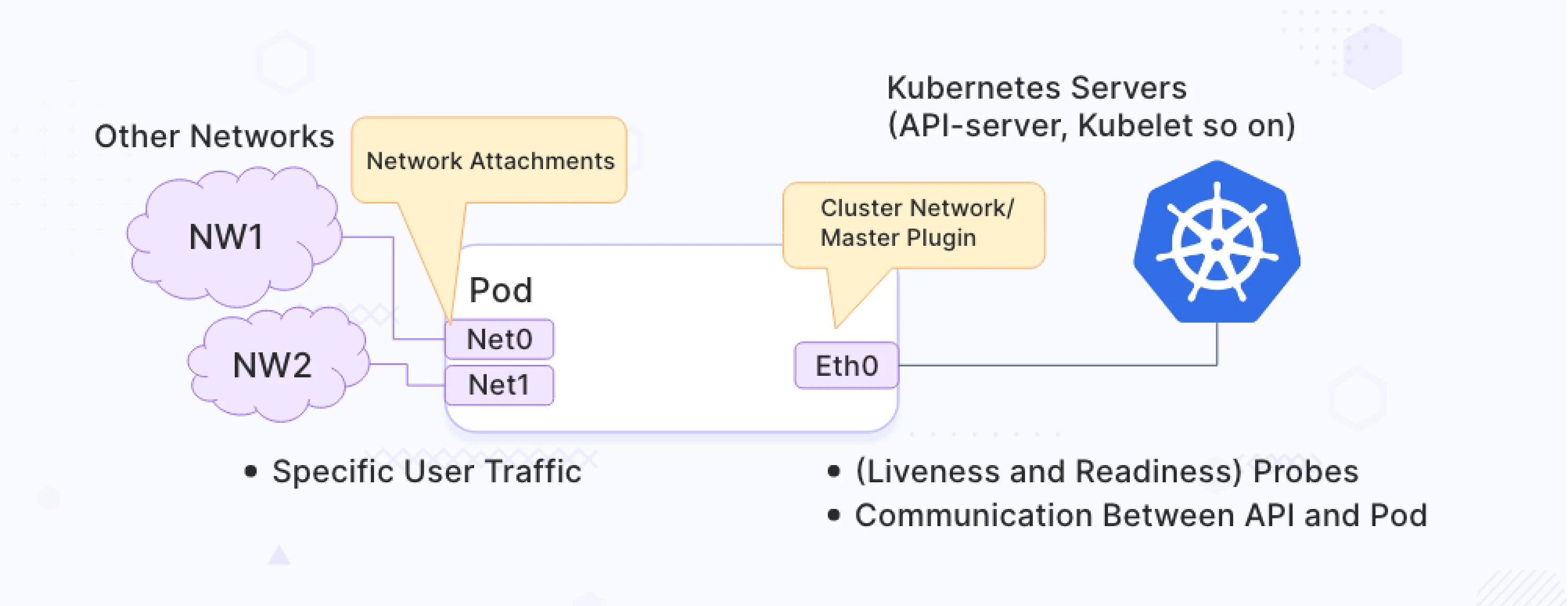
A pod with more than one network interface attached to it is called a multi-homed pod. The diagram below shows an illustration of a multi-homed pod, as provisioned by Multus CNI. The pod in the diagram has three interfaces: eth0, net0, and net1. Eth0 connects to the Kubernetes cluster for interacting with Kubernetes server/services. net0 and net1 are additional network attachments to other networks using other (secondary) CNI plugins.
2. IPAM CNIs
Secondary networks in Kubernetes, while crucial for complex AI/ML workloads, introduce a new challenge: managing IP addresses across these diverse network configurations. This is where IPAM (IP Address Management) CNIs come into play, addressing the shortcomings of the default Kubernetes networking approach.
The default Kubernetes networking relies on a single IPAM solution, often DHCP (Dynamic Host Configuration Protocol). While functional, DHCP might not be suitable for all secondary network scenarios. Different networks might have different subnet requirements, reservation strategies, etc. and some applications may also need static IP addresses.
The IPAM CNIs act as specialized plugins designed to manage IP addresses specifically within the context of secondary networks. They bridge the gap between the limitations of the default Kubernetes IPAM and the diverse needs of secondary network configurations.
Whereabouts CNI and NV-IPAM are two prominent options used by IPAM with the Network Operator.
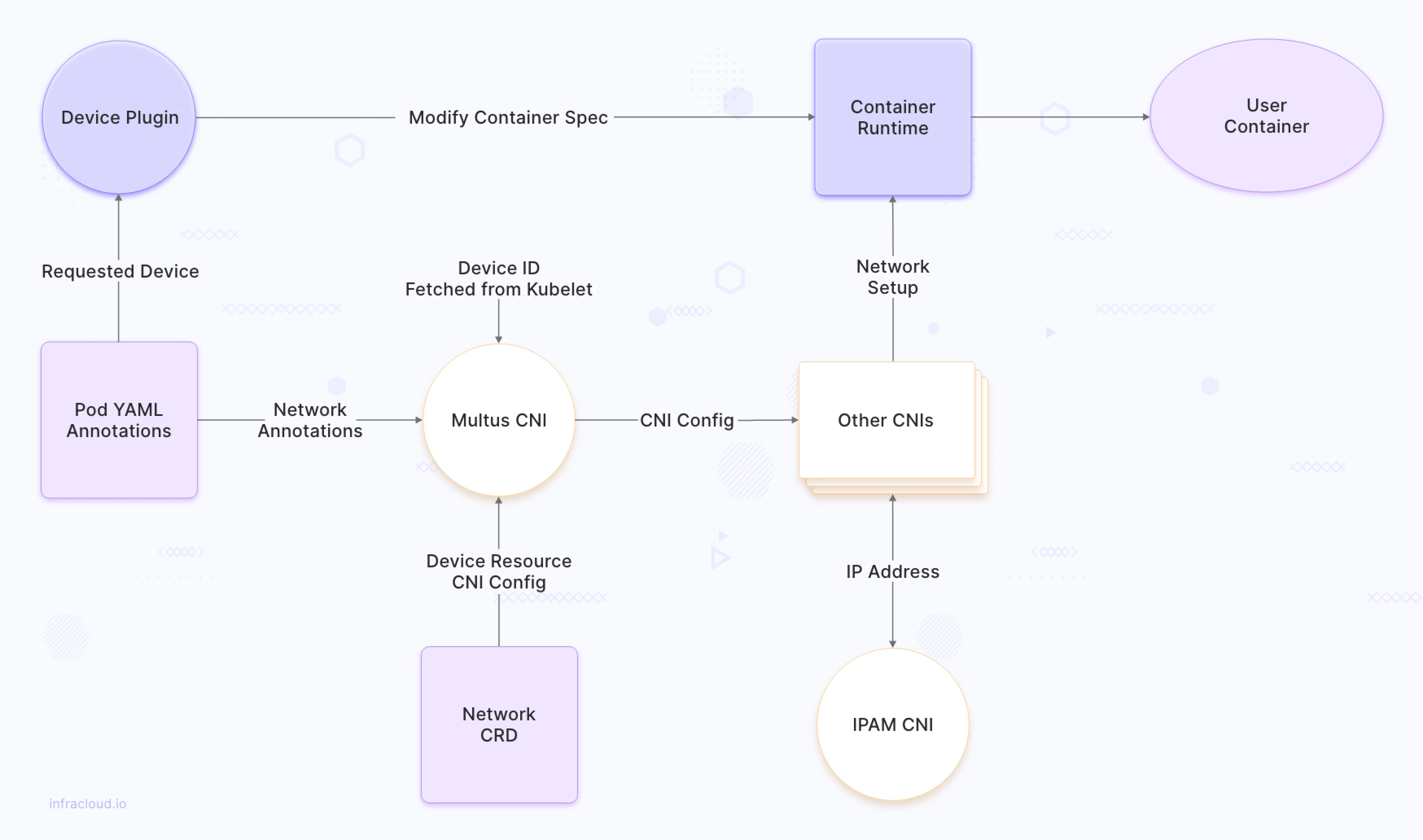
The above diagram depicts the network workflow for multi-homed pods on Kubernetes with the role of Multus CNI and IPAM CNIs in the workflow.
Summary
In this blog post, we explored the significant problems the Network Operator solves, such as automating the installation of various network solutions, providing a central place of configuration, automated updates, etc. We delved into its key features, highlighting how it simplifies network management and improves overall network performance. We explored some key CRDs and their specifications while also understanding secondary networks and CNIs and their role in high-performance computing.
In summary, the NVIDIA Network Operator, with its robust features and comprehensive management capabilities, is an indispensable tool for any organization looking to optimize their AI and ML workloads on Kubernetes. By leveraging the advanced networking solutions it provides, businesses can ensure their applications run efficiently, paving the way for innovation and growth in the AI/ML domain.
Now that you have learned about NVIDIA Network Operator, its features and key concepts, you can bring in AI & GPU Cloud experts to help you build your own AI cloud.
If you found this post useful and informative, subscribe to our weekly newsletter for more posts like this. We’d love to hear your thoughts on this post, so do start a conversation on LinkedIn with Sameer and Bhavin.
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like







{kind=link}