
Machine Learning (ML) Orchestration on Kubernetes using Kubeflow

MLOps: from proof of concepts to industrialization
In recent years, AI and Machine Learning (ML) have seen tremendous growth across industries in various innovative use cases. It is the most important strategic trend for business leaders. When we dive into a technology, the first step is usually experimentation on a small scale and for very basic use cases, then the next step is to scale up operations. Sophisticated ML models help companies efficiently discover patterns, uncover anomalies, make predictions and decisions, and generate insights, and are increasingly becoming a key differentiator in the marketplace. Companies recognise the need to move from proof of concepts to engineered solutions, and to move ML models from development to production. There is a lack of consistency in tools and the development and deployment process is inefficient. As these technologies mature, we need operational discipline and sophisticated workflows to take advantage and operate at scale. This is popularly known as MLOps or ML CI/ CD or ML DevOps. In this article, we explore how this can be achieved with the Kubeflow project, which makes deploying machine learning workflows on Kubernetes simple, portable, and scalable.
MLOps in cloud native world
There are Enterprise Machine learning platforms like Amazon SageMaker, Azure ML, Google Cloud AI, and IBM Watson Studio in public cloud environments. In case of on-prem and hybrid open source platform, the most notable project for Machine Learning (ML) Orchestration on Kubernetes is Kubeflow[https://www.kubeflow.org/].
What is Kubeflow?
Kubeflow is a curated collection of machine learning frameworks and tools. It is a platform for data scientists and ML engineers who want to experiment with their model and design an efficient workflow to develop, test and deploy at scale. It is a portable, scalable, and open-source platform built on top of Kubernetes by abstracting the underlying Kubernetes concepts.
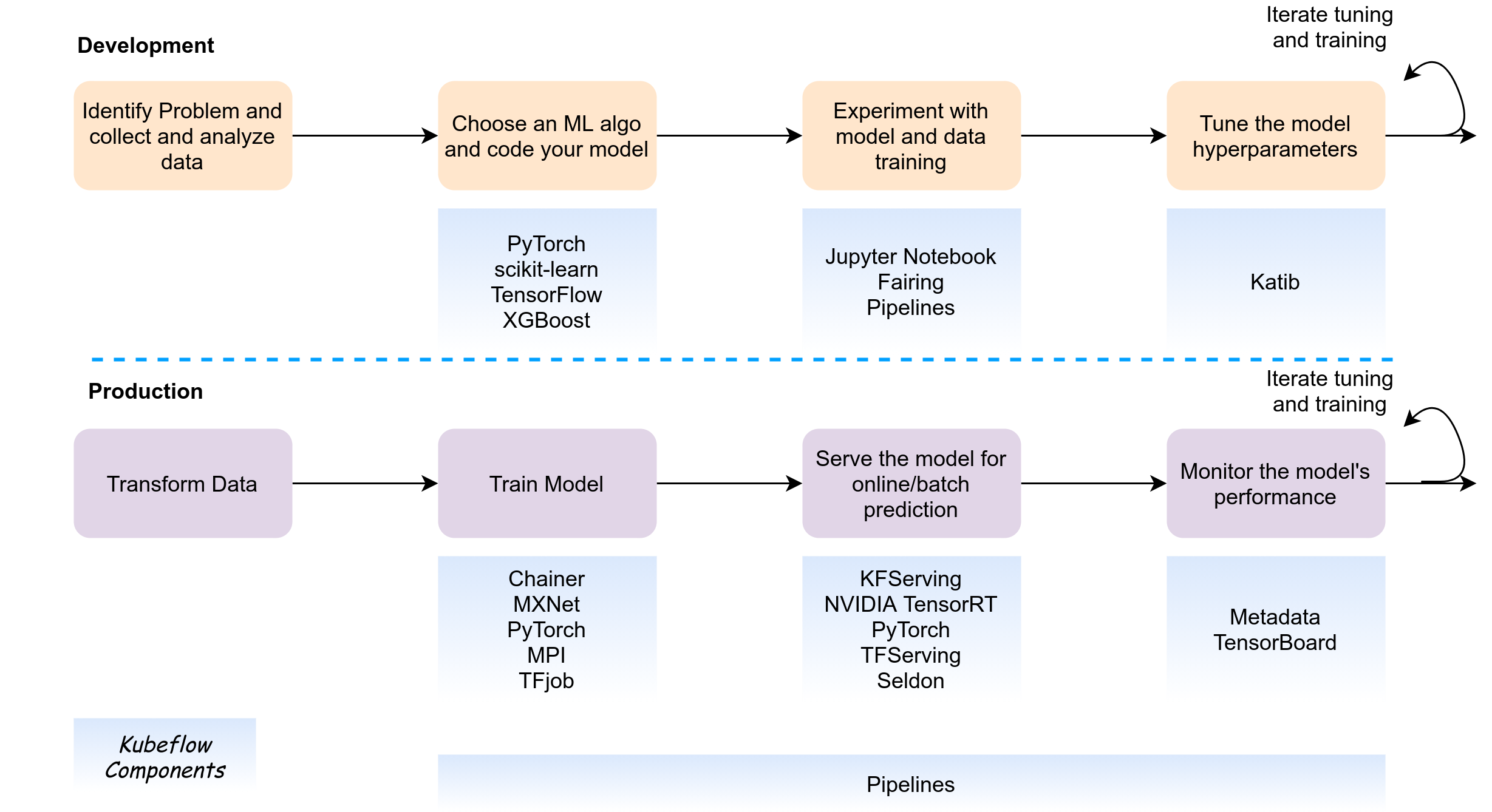
Kubeflow architecture
Kubeflow utilizes various cloud native technologies like Istio, Knative, Argo, Tekton, and leverage Kubernetes primitives such as deployments, services, and custom resources. Istio and Knative help provide capabilities like blue/green deployments, traffic splitting, canary releases, and auto-scaling. Kubeflow abstracts the Kubernetes components by providing UI, CLI, and easy workflows that non-kubernetes users can use.
For the ML capabilities, Kubeflow integrates the best framework and tools such as TensorFlow, MXNet, Jupyter Notebooks, PyTorch, and Seldon Core. This integration provides data preparation, training, and serving capabilities.

Let’s look at Kubeflow components
- Central Dashboard: User interface for managing all the Kubeflow pipeline and interacting with various components.
- Jupyter Notebooks: It allows to collaborate with other team members and develop the model.
- Metadata - It helps in organizing workflows by tracking and managing the metadata in the artifacts. In this context, metadata means information about executions (runs), models, datasets, and other artifacts. Artifacts are the files and objects that form the inputs and outputs of the components in your ML workflow.
- Fairing: It allows running training job remotely by embedding it in Notebook or local python code and deploy the prediction endpoints.
- Feature Store (Feast): It helps in feature sharing and reuse, serving features at scale, providing consistency between training and serving, point-in-time correctness, maintaining data quality and validation.
- ML Frameworks: This is a collection of frameworks including, Chainer (deprecated), MPI, MXNet, PyTorch, TensorFlow, providing
- Katib: It is used to implement Automated machine learning using Hyperparameters (variables to control the model training process), Neural Architecture Search (NAS) to improve predictive accurancy and performance of the model, and a web UI to interact with Katib.
- Pipelines: Provides end-to-end orchestration and easy to reuse solution to ease the experimentations.
- Tools for Serving: There are two model serving systems that allow multi-framework model serving: KFServing, and Seldon Core. You can read more about tools for serving here.
What are some of the Kubeflow use cases?
-
Hybrid multi-cloud ML Platform at scale: As Kubeflow is based on Kubernetes, it utilized all the features and power that Kubernetes provides. This allows you to design ML platforms that are portable and utilize the same APIs etc. to run on on-prem and public clouds.
-
Experimentation: Easy UI and abstration helps in rapid experimentation and collaboration. This speeds development by providing guided user journeys.
-
DevOps for ML platform: Kubeflow pipelines can help creating reproducible workflows which delivers consistency, saves iteration time, and helps in debugging, auditability, and compliance requirements.
-
Tuning the model hyperparameters during training: During model development, hyperparameters tuning is often hard to tune and time consuming. It is also critical for model performance and accuracy. Katib can reduce the testing time and improve the delivery speed by automating hyperparameters tuning.
Kubeflow demo
Let’s try to learn Kubeflow with an example. In this demo, we will try Kubeflow on a local Kind cluster. You should have at least 16GB of RAM, 8 CPUs modern machine to try it on your local machine, otherwise use a VM in cloud. We will use Zalando’s fashion MNIST dataset and this notebook by manceps for demo.
Due to some issue, I had to enable few feature gates and extra API server arguments to make it work. Please use the following Kind configuration to create the cluster.
# kind cluster configuration - kind.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
featureGates:
"TokenRequest": true
"TokenRequestProjection": true
kubeadmConfigPatches:
- |
kind: ClusterConfiguration
metadata:
name: config
apiServer:
extraArgs:
"service-account-signing-key-file": "/etc/kubernetes/pki/sa.key"
"service-account-issuer": "kubernetes.default.svc"
Create the Kind cluster and install Kubeflow.
# Create Kind cluster
kind create cluster --config kind.yaml
# Deploy Kubeflow on Kind.
mkdir -p /root/kubeflow/v1.0
cd /root/kubeflow/v1.0
wget https://github.com/kubeflow/kfctl/releases/download/v1.0/kfctl_v1.0-0-g94c35cf_linux.tar.gz
tar -xvf kfctl_v1.0-0-g94c35cf_linux.tar.gz
export PATH=$PATH:/root/kubeflow/v1.0
export KF_NAME=my-kubeflow
export BASE_DIR=/root/kubeflow/v1.0
export KF_DIR=${BASE_DIR}/${KF_NAME}
export CONFIG_URI="https://raw.githubusercontent.com/kubeflow/manifests/v1.2-branch/kfdef/kfctl_k8s_istio.v1.2.0.yaml"
mkdir -p ${KF_DIR}
cd ${KF_DIR}
kfctl apply -f ${CONFIG_URI}
It may take 15-20 minutes to bring up all the services.
❯ kubectl get pods -n kubeflow
NAME READY STATUS RESTARTS AGE
admission-webhook-bootstrap-stateful-set-0 1/1 Running 0 19m
admission-webhook-deployment-5cd7dc96f5-4hsqr 1/1 Running 0 18m
application-controller-stateful-set-0 1/1 Running 0 21m
argo-ui-65df8c7c84-dcm6m 1/1 Running 0 18m
cache-deployer-deployment-5f4979f45-6fvg2 2/2 Running 1 3m21s
cache-server-7859fd67f5-982mg 2/2 Running 0 102s
centraldashboard-67767584dc-f5zhh 1/1 Running 0 18m
jupyter-web-app-deployment-8486d5ffff-4cb8n 1/1 Running 0 18m
katib-controller-7fcc95676b-brk2q 1/1 Running 0 18m
katib-db-manager-85db457c64-bb7dp 1/1 Running 3 18m
katib-mysql-6c7f7fb869-c4qqx 1/1 Running 0 18m
katib-ui-65dc4cf6f5-qrjpm 1/1 Running 0 18m
kfserving-controller-manager-0 2/2 Running 0 18m
kubeflow-pipelines-profile-controller-797fb44db9-hdnxc 1/1 Running 0 18m
metacontroller-0 1/1 Running 0 19m
metadata-db-6dd978c5b-wtglv 1/1 Running 0 18m
metadata-envoy-deployment-67bd5954c-z8qrv 1/1 Running 0 18m
metadata-grpc-deployment-577c67c96f-ts9v6 1/1 Running 6 18m
metadata-writer-756dbdd478-7cbgj 2/2 Running 0 18m
minio-54d995c97b-85xl6 1/1 Running 0 18m
ml-pipeline-7c56db5db9-9mswf 2/2 Running 0 18s
ml-pipeline-persistenceagent-d984c9585-82qvs 2/2 Running 0 18m
ml-pipeline-scheduledworkflow-5ccf4c9fcc-mjrwz 2/2 Running 0 18m
ml-pipeline-ui-7ddcd74489-jw8gj 2/2 Running 0 18m
ml-pipeline-viewer-crd-56c68f6c85-tszc4 2/2 Running 1 18m
ml-pipeline-visualizationserver-5b9bd8f6bf-dj2r6 2/2 Running 0 18m
mpi-operator-d5bfb8489-9jzsf 1/1 Running 0 4m27s
mxnet-operator-7576d697d6-7wj52 1/1 Running 0 18m
mysql-74f8f99bc8-fddww 2/2 Running 0 18m
notebook-controller-deployment-5bb6bdbd6d-vx8tv 1/1 Running 0 18m
profiles-deployment-56bc5d7dcb-8x7vr 2/2 Running 0 18m
pytorch-operator-847c8d55d8-zgh2x 1/1 Running 0 18m
seldon-controller-manager-6bf8b45656-6k8r7 1/1 Running 0 18m
spark-operatorsparkoperator-fdfbfd99-5drsc 1/1 Running 0 19m
spartakus-volunteer-558f8bfd47-h2w62 1/1 Running 0 18m
tf-job-operator-58477797f8-86z42 1/1 Running 0 18m
workflow-controller-64fd7cffc5-77g6z 1/1 Running 0 18m
Now, you can access the Kubeflow dashboard by port-forwarding on http2/$INGRESS_PORT where can be fetched using below.
export INGRESS_PORT=$(kubectl -n istio-system get service istio-ingressgateway -o jsonpath='{.spec.ports[?(@.name=="http2")].nodePort}')
Let’s try an experiment
We will be using Zalando’s Fashion-MNIST dataset to show basic classification using Tensorflow in this experiment.
About the Dataset Fashion-MNIST is a dataset of Zalando’s article images—consisting of a training set of 60,000 examples and a test set of 10,000 examples. Each example is a 28x28 grayscale image associated with a label from 10 classes. We intend Fashion-MNIST to serve as a direct drop-in replacement for the original MNIST dataset for benchmarking machine learning algorithms. It shares the exact image size and structure of training and testing splits. source: https://github.com/zalandoresearch/fashion-mnist
The whole experiment is sourced from manceps notebook. Create a Jupyter notebook with the name kf-demo using this notebook.
You can run the notebook from the dashboard and create the pipeline. Please note, in Kubeflow v1.2, there is an issue causing RBAC: permission denied error while connecting to the pipeline. This will be fixed in v1.3 and you can read more about the about the connecting to the pipeline issue here. As a workaround, you need to create Istio ServiceRoleBinding and EnvoyFilter to add an identity in the header. Refer this gist for the patch.
The Kubeflow will orchestrate various components to create the pipeline and run the ML experiment. You can access the results through the dashboard. Behind the scene, Kubernetes pods, argo workflows, etc., are created which you don’t need to worry about.
 Pods running the kf-demo notebook and pipeline
Pods running the kf-demo notebook and pipeline
I also noticed that when running the Pipeline in Kind, it complained about the following:
MountVolume.SetUp failed for volume "docker-sock" : hostPath type check
failed: /var/run/docker.sock is not a socket file
To resolve this, I had to change the Argo Workflow ConfigMap to use pns instead of docker container runtime executor. 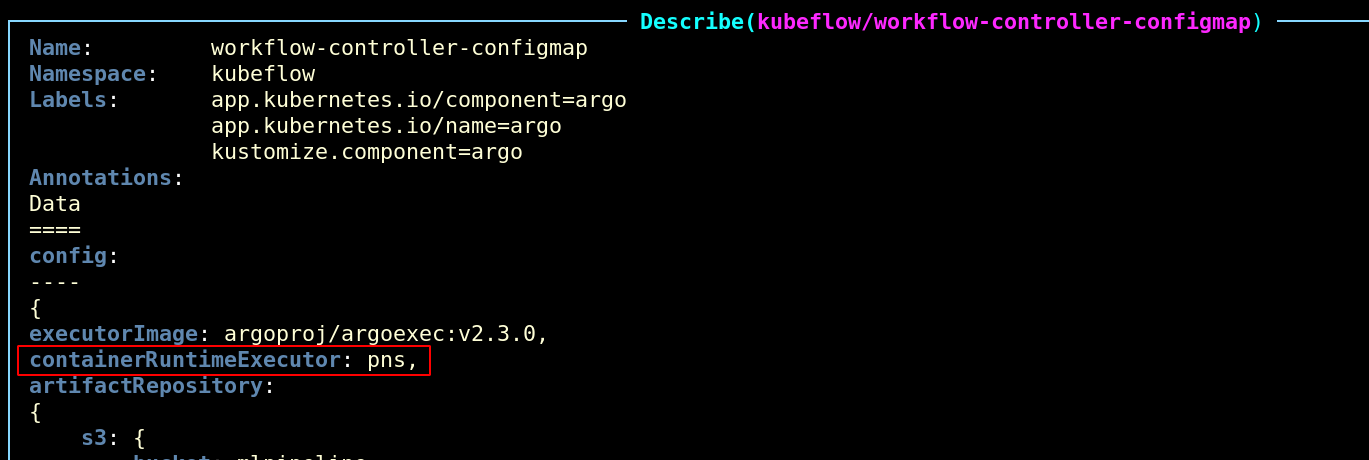
After the change, re-run the experiment from the dashboard, which will then passthrough.
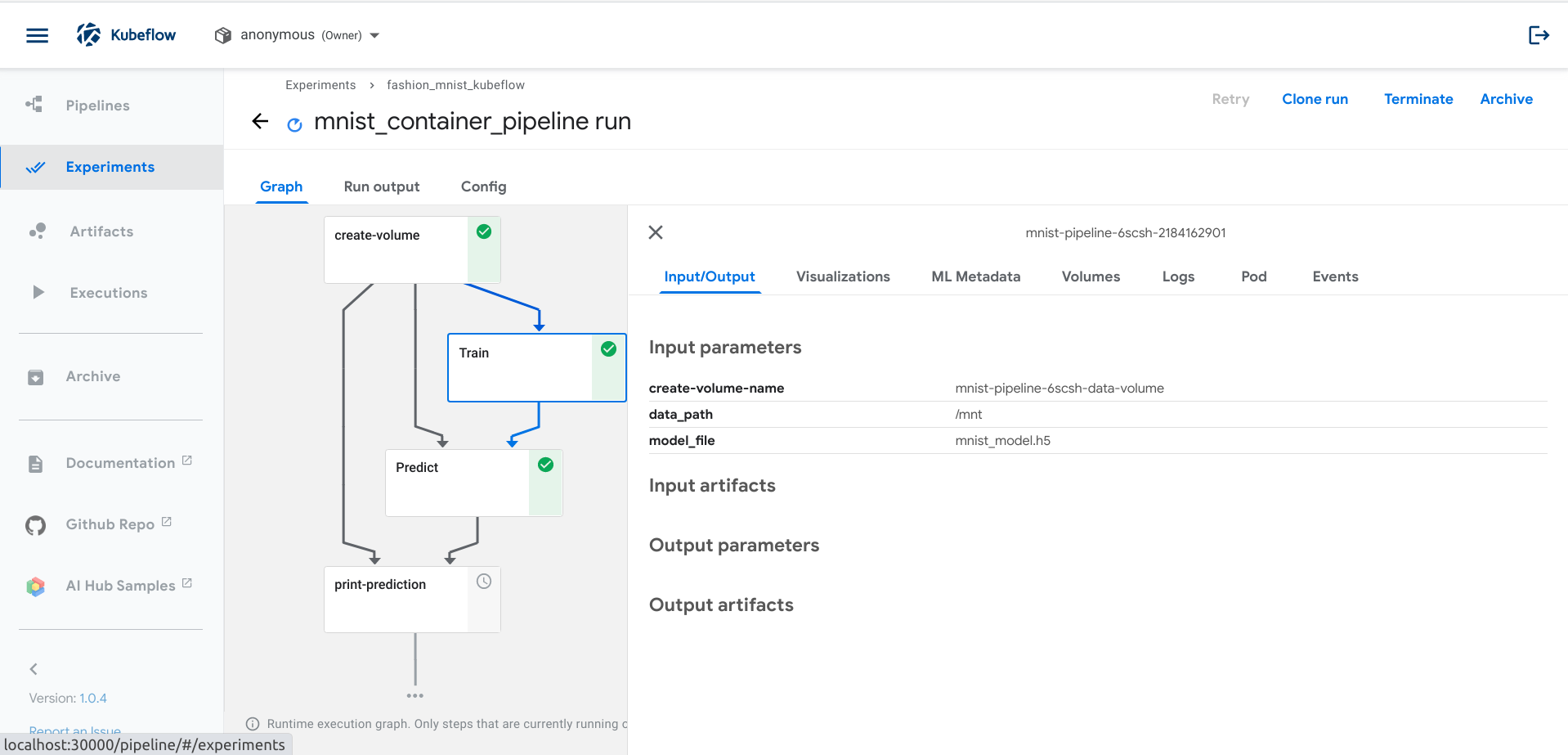 Experiment Flow
Experiment Flow 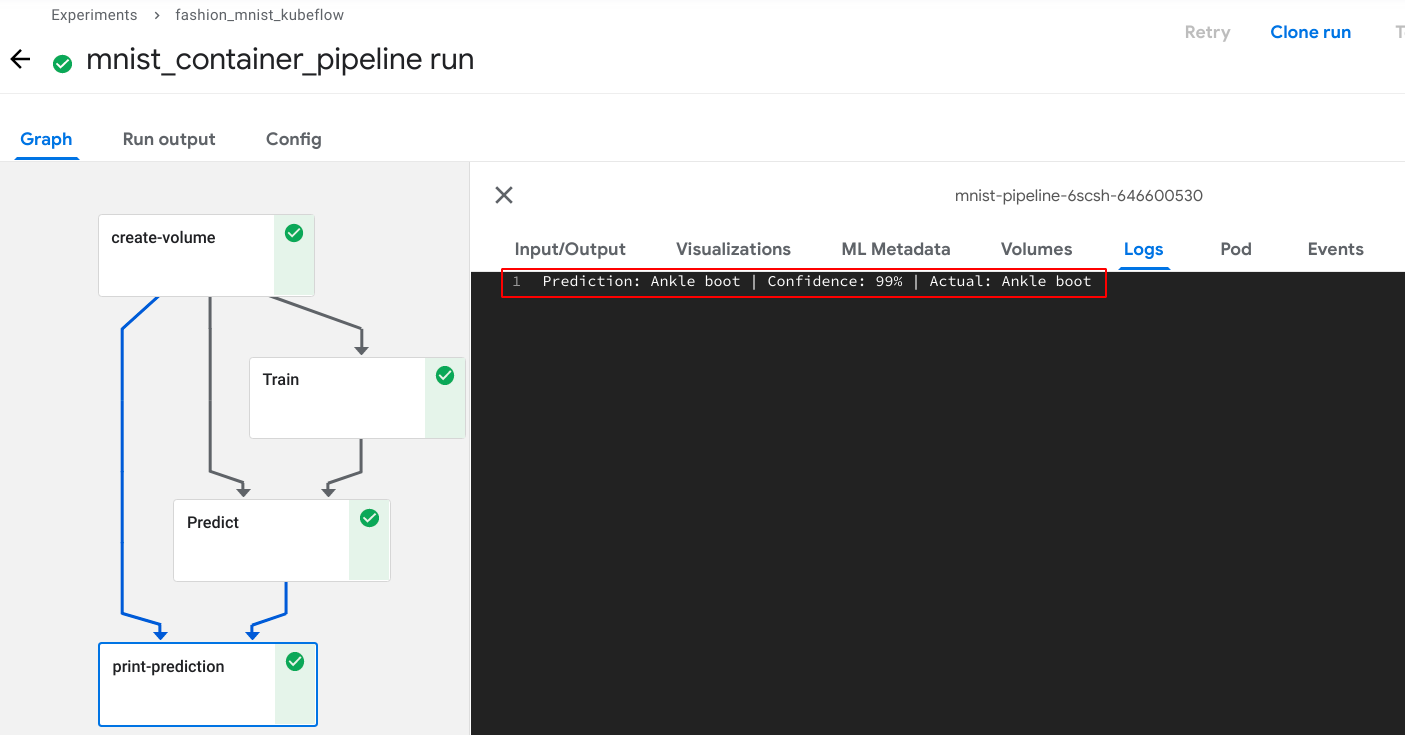 Prediction Result
Prediction Result
Conclusion
If you are looking for bringing agility, improved management with enterprise-grade features such as RBAC, multi-tenancy and isolation, security, auditability, collaboration for the machine learning operations in your organization, Kubeflow is an excellent option. It is stable, mature and curated with best-in-class tools and framework which can be deployed in any Kubernetes distribution. See Kubeflow roadmap here to look into what’s coming in the next version.
Do try deploying machine learning workflows on Kubernetes in simple, portable, and scalable way using Kubeflow. Hope this blog post was helpful to you. Share your experience by connecting with me on Twitter.
Looking for help with Kubernetes adoption or Day 2 operations? do check out how we’re helping startups & enterprises with our Kubernetes consulting services and capabilities.
References
- https://www.gartner.com/smarterwithgartner/gartner-top-strategic-technology-trends-for-2021/
- https://www2.deloitte.com/content/dam/insights/articles/6730_TT-Landing-page/DI_2021-Tech-Trends.pdf
- https://www.crn.com/news/cloud/5-emerging-ai-and-machine-learning-trends-to-watch-in-2021?itc=refresh
- https://www.cncf.io/blog/2019/07/30/deploy-your-machine-learning-models-with-kubernetes/
- https://events19.linuxfoundation.org/wp-content/uploads/2018/02/OpenFinTech-MLonKube10112018-atin-and-sahdev.pdf
- https://thenewstack.io/how-kubernetes-could-orchestrate-machine-learning-pipelines/
- https://cloud.google.com/community/tutorials/kubernetes-ml-ops
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like







