
Prometheus HA with Thanos Sidecar Or Receiver?

Prometheus has been the flag bearer for monitoring the systems for a long time now. It has proved itself as a go-to solution for monitoring and alerting in Kubernetes systems. Though Prometheus does have some general instructions to achieve high availability within itself, it comes with its own limitations in data retention, historic data retrieval, and multi-tenancy. And this is where Thanos comes into the picture. In this blog post, we will go through the two different approaches for integrating Thanos with Prometheus in Kubernetes environments and will explore why one should go with a specific approach. Let’s get started!
Along with Thanos, another open source project named Cortex is also a popular alternative solution. An interesting fact is that initially, Thanos supported only sidecar installation, and Cortex preferred the push-based or remote write approach. But back in 2019, both the projects collaborated, and after learning and influencing each other (sharing is caring), that’s where a receiver component was added to Thanos, and the Cortex blocks storage has been built on top of a few core Thanos components.
Thanos in general
Thanos supports its integration with Prometheus in two ways:
- Sidecar
- Receiver
With following common components in Thanos Stack:
- Querier
- Store
- Compactor
- Ruler
Both Sidecar and Receiver are the different components in the Thanos stack and have their own way of functioning. But in the end, it serves the same purpose. Before comparing the approaches, let’s get to know in short how exactly both Sidecar and Receiver work.
Let’s start with the sidecar.
How does Thanos Sidecar approach work?
In the Sidecar approach, the Thanos Sidecar component as the name implies runs as a sidecar in more than one Prometheus server pod, be it vanilla Prometheus or Prometheus managed by the Prometheus Operator. This component is responsible for data delivery (from Prometheus TSDB) to object storage.
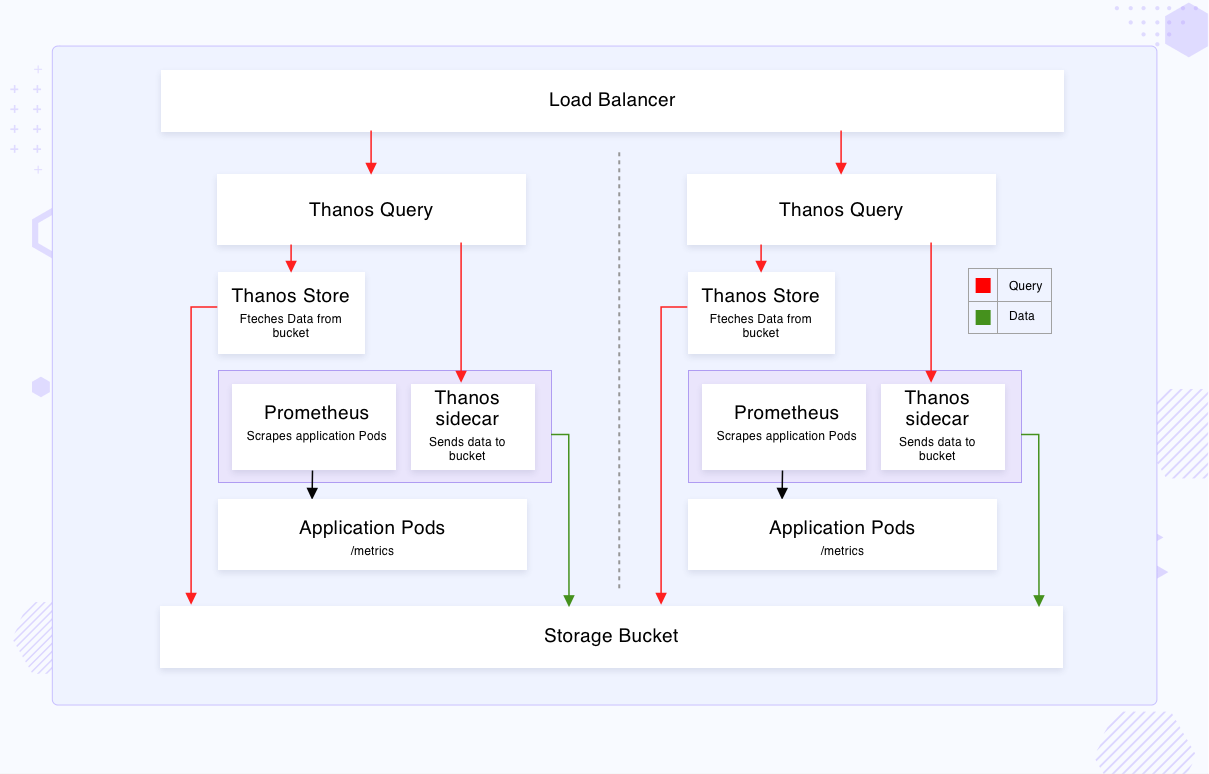
As shown in the layout above, for high availability, more than one Prometheus instance is provisioned along with the Sidecar component. Both the Prometheus instances scrape the metrics independently from the targets. The scraped TSDB blocks, by default, are stored in the storage provisioned to the Prometheus (Persistent Volumes).
Sidecar implements Thanos’ Store API on top of Prometheus’ remote-read API, making it possible to query the time series data in Prometheus servers from a centralized component named Thanos Querier. Furthermore, the sidecar can also be configured to upload the TSDB blocks to object storage at an interval of two hours, blocks are created every two hours. The data stored in the bucket can be queried using the Thanos Store component, this implements the same Store API and needs to be discovered by Thanos Querier.
For detailed information on the sidecar, please refer to our another blog post Making Prometheus Highly Available (HA) & Scalable with Thanos
How does Thanos Receiver approach work?
The Receiver is provisioned as an individual StatefulSet, unlike sidecar. In this approach, all the other components of the Thanos stack exist and function the same way as the sidecar approach, but the Receiver replaced the Sidecar component. The way TSDBs are queried and transferred to object storage has a drastic change.
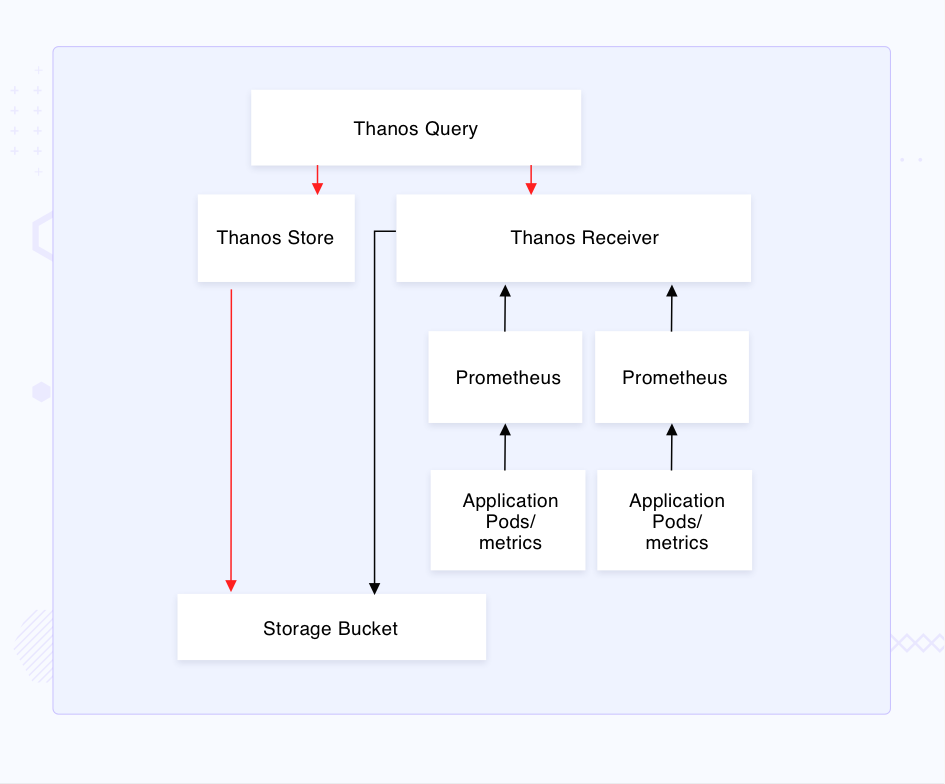
The Prometheus Remote Write API is put into use, such that the Prometheus instances are configured to continuously write remotely on the Receiver. The receiver is configured to populate the object storage bucket and also has its own retention period. Querier is configured to query data on the Receiver and storage bucket via Store.
Integrating Receiver is a bit trickier compared to Sidecar, for more details for setting up the receiver take a look at the blog post Achieve Multi-tenancy in Monitoring with Prometheus & Thanos Receiver.
Let’s compare Sidecar and Receiver
Let’s do 1:1 comparison of Thanos Sidecar and Receiver for achieving Prometheus HA, compares the both on the various aspects like High Availability, integrations with Prometheus, storage, and data acquisition.
High Availability
Sidecar
High availability (HA) is acquired by integrating sidecar containers with each replica of Prometheus instance. Each instance individually scrapes the target, and sidecar uploads the blocks to objects storage. Prometheus writes a TSDB block every two hours, considering there are two Prometheus replicas and one goes down, the latest in construction block will be lost. This generally will show a void in the graph for this specific Prometheus instance. But since there are two replicas, that void is filled with the data from another Prometheus instance’s block. Thanos Querier takes care filling these gaps and deduplication.
Receiver
Similar to Sidecar, multiple Prometheus instances are deployed to scrape the same targets and are configured to write remotely to Receiver StatefulSet. Here, not only Prometheus replicas but also Receiver replicas play a vital role in HA. Apart from that, the Receiver also supports multi-tenancy. Consider setting a replication factor=2, this would ensure that the incoming data gets replicated between two Receiver pods. Failure of a single Prometheus instance is covered by another since both write remotely to the Receiver. Failure of a single Receiver pod is compensated by other due to the replication factor being two.
Integration with Prometheus
Sidecar
A simple addition of a sidecar container in the Prometheus instance pod is all that needs to be done, and all the other Thanos components work along with it. The sidecar optionally writes a TSDB block every two hours to the storage. Generally, a number of sidecars are exposed as a service to the Thanos Querier by simply adding the endpoint under the Querier configuration. Data stored in buckets is exposed via the Store component. Thus, integrating Sidecar is quite easy and suitable for most of the scenarios.
Receiver
This needs configuration changes in the Prometheus instance to remote write the TSDBs to the Receivers along with deploying an additional Receiver StatefulSet. The Receiver retains the TSDBs on local storage for the value of --tsdb.retention flag. Achieving load-balancing and data replication needs running multiple instances of Thanos Receiver as a part of a hashring. Configuration of hashring such that there are exclusive Receiver endpoints for matching tenant header in the HTTP request is needed. Integrating the Receiver is a complex and tedious task.
Storage
Sidecar
Sidecar reads from the Prometheus’ local storage, so no additional local storage (PVs) are required for TSDBs. Additionally, it considerably reduces the retention time of TSDBs in Prometheus local storage since it uploads every two hours while their historic data is made durable and queryable via object storage. By default, Prometheus stores the data for 15 days. In the case of monitoring a complete, heavy production cluster, it would require a considerable amount of local storage, and the local storage is comparatively expensive than object storage (EBS volumes are expensive than S3 buckets).
Since Sidecar exports Prometheus metrics every 2 hours to buckets, it brings the Prometheus closer to being Stateless. Though in Thanos docs, the retention of Prometheus is recommended to not be lower than three times the min block duration, so it becomes 6 hours.
Receiver
The Receiver, being a StatefulSet needs to be provisioned with PVs. The amount of local storage required here is dependent on the flags --receive.replication-factor, --tsdb.retention, and pod replicas of the StatefulSet. Higher the TSDB retention, more of the local storage will be utilized. Since the data is being continuously written to the Receiver, the Prometheus retention could be kept at the minimum value. This setup needs more local storage compared to Sidecar.
Data acquisition
Sidecar
Here the TSDB block is read from the local storage of the Prometheus instance, either served to the Querier for querying or exported to the object storage intermittently. Sidecar works on a pull-based model (Thanos Querier pulls out series from Prometheus at query time), and the data is not constantly written to any other instance.
Receiver
Receiver works on push based model, TSDBs are written remotely by the Prometheus instance itself to the Receiver continuously, hence bringing the Prometheus closest it can to be stateless. Data is then further uploaded to object storage from the Receiver. Pushing the metrics comes with its own pros and cons which are discussed here, and is recommended to be used mostly in air-gapped, or egress only environments.
Conclusion - Sidecar or Receiver for Prometheus HA?
Selecting a type of approach is entirely subjective to the environment in which Prometheus HA and multitenancy are to be achieved. In a case where Prometheus High Availability (HA) needs to be achieved for a single cluster or using a Prometheus Operator for specific application monitoring, Sidecar seems to be a good option due to its ease of operation and lightweight integration. Sidecar can also be used for multi-tenancy via layered Thanos Querier approach.
Whereas in case a more centralized view of multiple tenants is required or in egress only environments, one can go with Receiver after considering the limitations of pushing the metrics. Achieving a global view of a single-tenant is not recommended via Receiver. When trying to achieve a global view of multiple tenants with different environment limitations, one can go with a hybrid approach of using both Sidecar and Receiver.
We hope you found this post informative and engaging. Connect with us over Twitter and Linkedin and start a conversation.
Looking for help with observability stack implementation and consulting? do check out how we’re helping startups & enterprises as an observability consulting services provider.
References and further reading
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like










