
Gluster Storage with Heketi for Kubernetes

Introduction
One of key areas when running containers using Kubernetes is managing the stateful applications such as a database. We use Gluster along with Kubernetes in this post and demonstrate how you can run stateful applications on Kubernetes
GlusterFS and Heketi
GlusterFS is an open-source scalable network FileSystem which can be created using off the shelf hardware. Gluster allows creation of various types of volumes such as Distributed, Replicated, Striped, Dispersed and many combinations of these which are described in detail here.
Heketi is a Gluster Volume manager that provides RESTful interface to create/manage Gluster volumes. Heketi makes it easy for cloud services such as Kubernetes, OpenShift, OpenStack Manila to interact with Gluster clusters and provision volumes as well as manage brick layout.
Use case overview
The purpose of this post is to demonstrate how to create a GlusterFS cluster, manage this cluster using Heketi to provision volumes and then install a demo application to use the Gluster volume.
We shall create a 4 node Kubernetes cluster with two unformatted disks on each node. We shall then install glusterFS as DaemonSet and heketi as a service to create gluster volumes which will be consumed by a Postgres database using StatefulSet. We shall have another application which adds 1 entry per second to the Postgres DB and a flask application that will allow us to view the contents of the Database. We shall also move the postgresdb from one node to another and still be able to access our data.
Implementation Steps
Prerequisites:
- A Google Cloud Platform Account with admin privileges
- API should be enabled on GCP account.
Kubernetes Cluster creation and bootstrapping:
- Log on to Google Cloud console and Open Google Cloud Shell

- Create a directory called “gluster-heketi” and cd gluster-heketi
- Clone the git repo using following command:
git clone https://github.com/infracloudio/gluster-heketi-k8s.git .
- Edit “cluster_and_disks.sh” and change the variable PROJECT_ID to your GCP project.
- CLUSTER_NAME, ZONE and NODE_COUNT variables can be changed if needed.
- Execute the script “cluster_and_disks.sh”
This will create a 4 node GKE cluster and each node will have 2 unformatted disks attached to it. This script will also generate a topology file which is going to be used as a kubernetes configmap. The topology contains details of kubernetes nodes in the cluster and their mounted disks.
Note: Following these steps will create resources which are chargeable by GCP. Ensure to follow cleanup steps mentioned below to delete all resources once done with the demo.
Setting up Gluster, Heketi and Storage Class
- In Netowrk configuration, create a Firewall rule called “allow-heketi” and open ports as shown below
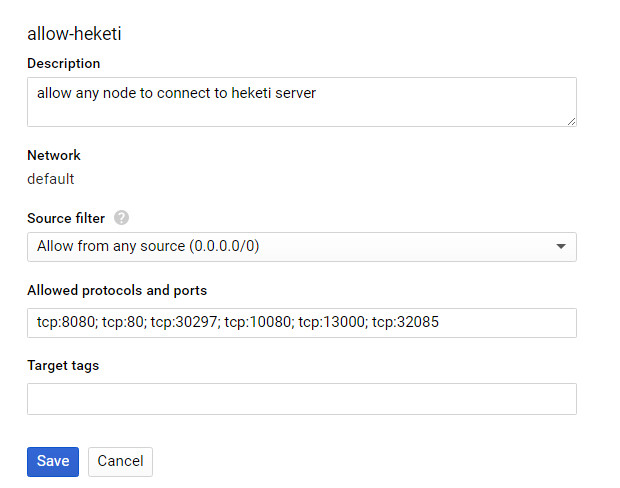
-
Run following command to import the configmap in kubernetes
kubectl create -f heketi-turnkey-config.yaml -
Run following command to start a gluster daemon set and install heketi service. This creates a temporary pod which is based on container created by Janos Lenart
kubectl create -f heketi-turnkey.yaml
- Process logs of this pod can be viewed using below command
kubectl logs heketi-turnkey -f
- Above yaml file will create a daemonset with gluster installation which will take control of all nodes and devices mentioned in the topology file. It will also install heketi as a pod and expose the heketi API via a service.

- Next step is creation of Storage Class through which will allow dynamic creation of gluster volume by calling heketi service. Following steps need to be done in order to correctly set up the storage class:
- Note the node port of heketi service as shown below:

-
- Open firewall for this port in allow-heketi Firewall Rule as shown below:
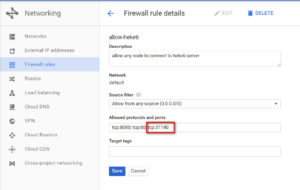
- Note the public IP of one of the Kubernetes nodes and update rest URL key in “storage_class.yaml” with public IP of a node and Node port from above (In real world implementation you might have a Domain name for Kubernetes cluster endpoint). For example:
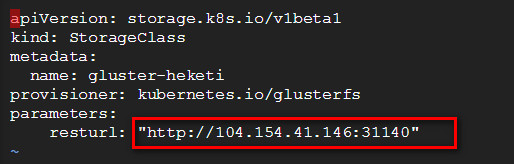
- Open firewall for this port in allow-heketi Firewall Rule as shown below:
-
Now run “kubectl create -f storage_class.yaml” so kubernetes can talk to heketi in order to create volumes as needed.
-
Next, run “kubectl create -f postgres-srv-ss.yaml” this will create a postgres pod in a StatefulSet. This Stateful set is backed by a gluster volume. The configuration to achieve this is shown below:
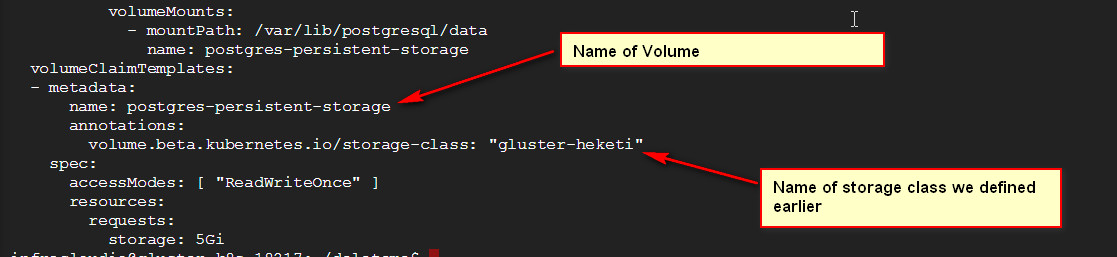 . This StatefulSet is exposed by a service name called “postgres”.
. This StatefulSet is exposed by a service name called “postgres”. -
Run “kubectl get pvc” to check if the volume got created and bound to the pod as expected. The result should look like below:

-
Run “kubectl create -f pgwriter-deployment.yaml”. This will create a deployment for a pod which will write 1 entry per second to the postgres db created above.
-
Run “frontend.yaml”. This will create a deployment of a flask-based frontend which will allow querying the postgres DB. A external LoadBalancer is also created to front the service.
-
Enter the LoadBalancer IP in browser to access the front end. Enter HH:MM of previous minute (system time) and click Submit. A list of entries with timestamps and counter values is shown.
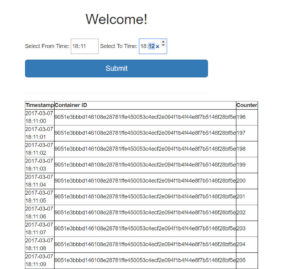
-
Run “kubectl describe pod postgres-ss-0” and note the Node on which the pod is running.

-
Now we will delete the statefulset (effectively the DB) and then create it again. Run following commands:
- kubectl delete -f postgres-srv-ss.yaml
- kubectl create -f postgres-srv-ss.yaml
-
Run “kubectl describe pod postgres-ss-0” and observe that the pod is assigned to a new node.

- Go back to the frontend and put the same HH:MM as before. The data can be observed to be intact despite host movement of the database.
Clean up:
- Run below command to delete the LoadBalancer:
kubectl delete -f frontend.yaml
- Delete the GKE cluster
- Once the GKE cluster is deleted, Delete the disks
Conclusion:
Heketi is a simple and convenient way to create and manage gluster volumes. It pairs very well with Kubernetes storage classes to give an on-demand volume creation capability which can be used with other gluster features such as replication, striping etc to handle many complex storage use cases.
Looking for help with Kubernetes adoption or Day 2 operations? learn more about our capabilities and why startups & enterprises consider as one of the best Kubernetes consulting services companies.
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like










