
3 Kubernetes Autoscaling Projects to Optimize Costs

First of all my apologies for choosing a catchy headline – as much as I have derided such posts, I genuinely had only three things to talk about which I felt had a connection and added value to many users and their workloads. Autoscaling is often not as clearly understood as I think it should be, at least by the consumers who may not want to understand all the nuts and bolts of how it works. Autoscaling can be of the application work units (Pods in case of Kubernetes) and of the nodes – which form the underlying infrastructure. The application work units – or pods in case of Kubernetes also need slightly different treatment based on the kind of workloads. The workloads can be divided into two broad categories – the synchronous workloads such as the HTTP server responding to requests in realtime. The second kind of workload is which is more async in nature such as a process being invoked when a message arrives in a message queue. Both workloads need different ways to scale and be efficient.
In this post, we will talk about each of the three Kubernetes autoscaling use cases, which projects solve these problems when using them, etc. For a quick summary, we will cover three aspects:
- Autoscaling Event-driven workloads
- Autoscaling real-time workloads
- Autoscaling Nodes/Infrastructure
Autoscaling Event-Driven Workloads in Kubernetes
For these workloads, the events are generated from a source and they land typically in some form of a message queue. Message queue enables handling scale as well as to manage back pressure etc. gracefully and divide the workload among many workers. The implementation of consumer and scaling is to an extent coupled with the message queue being used here. Also, many organizations may have more than one message queue in use.
The ideal scenario here would be that when there are no messages in the queue, the consumer pods are scaled down to zero. When messages start arriving the consumer pods are scaled up from zero to one and beyond one based on messages arriving.
One project that solves this problem nicely is the Keda project. We recently integrated Keda in the Fission project – which is a FaaS platform that works on Kubernetes. We also open-sourced the generic Keda connectors which enable you to consume messages from message queues and do generic things such as sending that message to an HTTP endpoint.
I also recently gave a talk where Keda was used to autoscale ACI (Azure Container Instance) containers using Keda from within a Kubernetes cluster using Virtual Kubelet. You can find the talk here and the slides here.
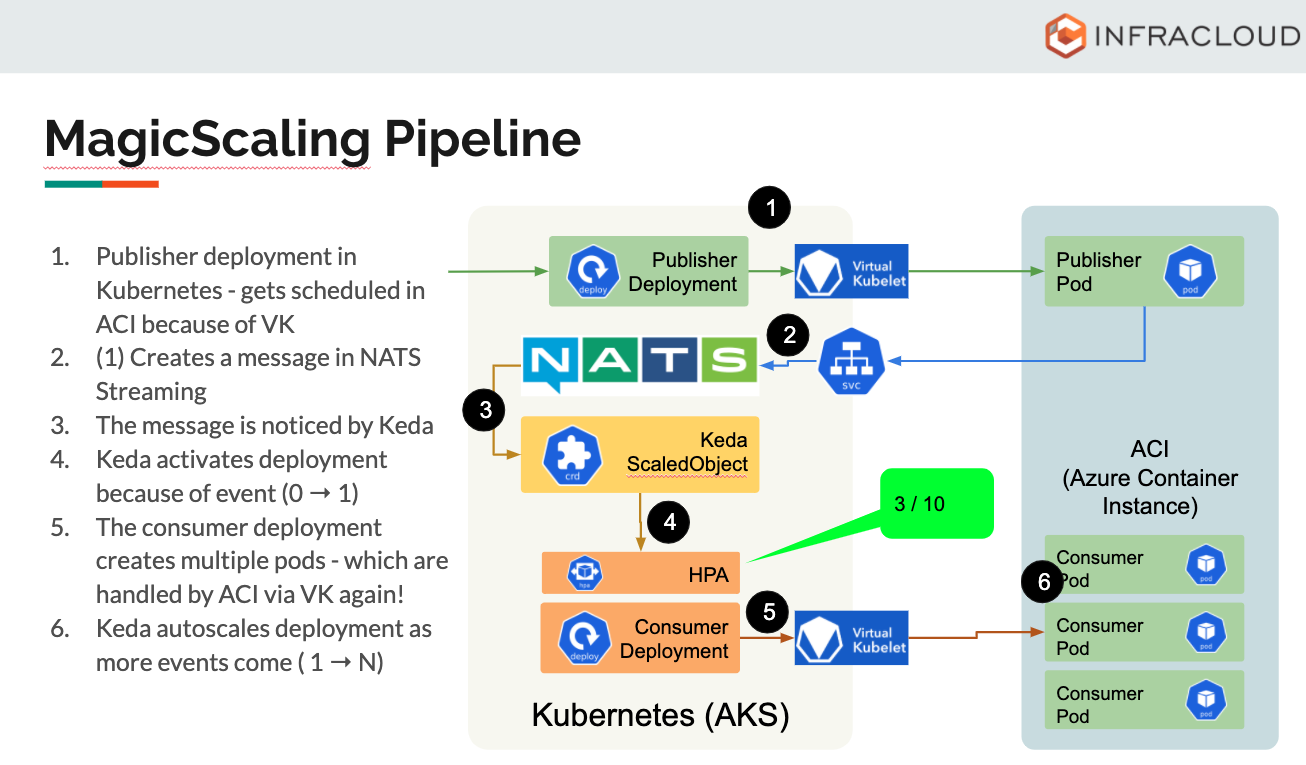
Autoscaling Realtime Workloads in Kubernetes
Many times you want to scale down the HTTP servers to zero or based on demand so that you can conserve infrastructure or use for some other workloads which will be processed in off-peak hours etc. While it is relatively easy for event-driven workloads, it is not so straightforward for realtime workloads. On one hand you don’t want the end-user to wait for the pods to spin up etc. – so this is definitely not recommended for usage in production. This can be used though effectively in stage/dev environments especially when your users are not going to consume the resources.
Scaling down the standard HPA along with the monitoring system will give you enough to get it working. You can see this in action in a talk given by Hrishikesh here and the presentation can be found here.
If you must scale to zero there are projects like Osiris – which are highly experimental but can be still useful for non-prod workloads and to optimize the infrastructure usage.
Autoscaling Nodes/Infrastructure in Kubernetes
Once you have optimized the workloads, the next natural step is to optimize the underlying infrastructure. All the benefits of optimizing the workloads can be only derived only if you can actually shut down a few instances and save some $$$! Especially for non-prod workloads – this can be a great cost-saving exercise.
There are definitely details here and the second part of a talk given by one of the InfraCloud members here discusses these things in detail. The Kubernetes Autoscaler project gives you all tools and levers to manage the infrastructure and scale it up and down based on need.
While we are on the topic of cost-saving in your Kubernetes clusters, you might also want to check out when to switch from CloudWatch to Prometheus – details in this post!
Bonus
There are some interesting projects on KubeCost Github repo that enable things such as turning down the clusters at a specific schedule etc. They can be a great compliment to the other three projects and also give you visibility of cluster usage & costs. Here’s a handy blog which talks more on Kubernetes cost reporting using Kubecost.
Summary
- Autoscaling can be of workloads & the underlying nodes/infrastructure. To save costs in pre-prod environments you will need to look at both aspects.
- For autoscaling event-driven workloads
- Keda project enables and can be used in production too effectively.
- For autoscaling real-time workloads
- Projects such as Osiris enable it but is not recommended for production workloads!
- The real value will be realized only after scaling underlying nodes/infrastructure and Kubernetes Autoscaler enables that. While you can use this in production too – the right design and testing are crucial to avoid costly mistakes and get it right.
Enjoyed the post? Let’s connect on Twitter and start a conversation.
Looking for help with Kubernetes adoption or Day 2 operations? learn more about our capabilities and why startups & enterprises consider as one of the best Kubernetes consulting services companies.
References & Images used from:
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like







