How to Build Scalable AI Systems in the Cloud

Traditional infrastructure often struggles to meet compute-intensive processing demands, unpredictable resource demands, and the data velocity of complex AI models. An AI cloud, particularly a GPU-based cloud platform, overcomes these shortcomings by offering extremely elastic computational resources, high-performance storage, and scalable infrastructure optimized for both AI training and inference. In contrast to generic compute-based traditional cloud infrastructures, a GPU cloud is specifically designed to host and scale AI workloads efficiently, enabling large-scale parallel processing as well as dynamic resource allocation. AI cloud enables teams to execute large model training jobs, serve inference at scale, and iterate more quickly without overprovisioning or exceeding infrastructure limits.
In this blog post, we will explore how companies are using AI cloud to address the unique scalability challenges of AI workloads. We will also discuss the cloud-native architectures, infrastructure optimization, and deployment patterns that provide seamless scalability for AI workloads.
Understanding AI workload scalability challenges
AI workloads pose many challenges and demand cloud-native solutions. The following are the key AI workload scalability challenges that businesses face when scaling AI:
Compute-intensive nature of AI/ML processes
AI workloads, particularly deep learning models (e.g., GPT-4, Stable Diffusion), are computationally resource-intensive and require extensive parallel computation both for training and inference stages, often beyond what traditional infrastructure can efficiently support. As model complexity increases, especially with LLMs containing billions of parameters, effectively configuring, distributing, and managing AI workloads across diverse hardware resources like CPUs, GPUs, and TPUs becomes increasingly challenging. Overall, it leads to infrastructure inefficiencies, longer training times, and delayed AI development cycles.
Unpredictable resource demands across the AI lifecycle
AI workloads provide unique scaling issues, with resource demands changing 10-100x across lifecycle phases, beyond the 2-5x range of traditional systems. Training large models can take weeks, dozens of GPUs, and terabytes of memory, whereas inference requires substantially less. Hyperparameter tuning increases complexity when multiple concurrent, compute-intensive experiments are executed, further complicating resource planning.
Traditional auto-scaling challenges with sudden increases in GPU or TPU demand. Hence, teams face a trade-off between costly over-provisioning and delays from under-provisioning. Furthermore, a typical infrastructure solution often lacks the flexibility required to dynamically manage specialized hardware and high-throughput data efficiently for AI development.
Data volume and velocity considerations
The sheer velocity and volume of data introduce operational and architectural challenges to AI workloads, often pushing data pipelines beyond the capabilities of traditional infrastructures. Scaling high-throughput, low-latency pipelines can be challenging; they must handle data surges, maintain consistency, and remain cost-effective. Processing petabyte-scale data, such as autonomous vehicle sensor streams, requires distributed data frameworks such as Apache Spark or Flink, whose deployment involves complex orchestration, resource balancing, and fault tolerance. Additionally, designing architectures that combine batch and streaming data (e.g., using lakehouses or tiered storage) requires significant planning and management. Our blog post on data management in the AI cloud explores these challenges further.
Performance bottlenecks in traditional infrastructure
Traditional infrastructure does not have the horizontal scalability and flexibility needed to accommodate AI intermittent workload patterns, resulting in resource underutilization during low-demand periods and performance bottlenecks during high-demand, ultimately slowing iteration cycles and time to value. For instance, storage I/O bottlenecks slow the entire data pipeline.
The challenges highlight why adopting cloud-native principles like containerization, dynamic orchestration, microservices-based architecture, service decoupling, distributed computing frameworks, etc, is critical for modern AI workloads. In the next section, we will see a few strategies to help AI cloud tackle these challenges.
How is AI cloud solving scalability challenges?
AI clouds address the challenges mentioned above with the following strategies:
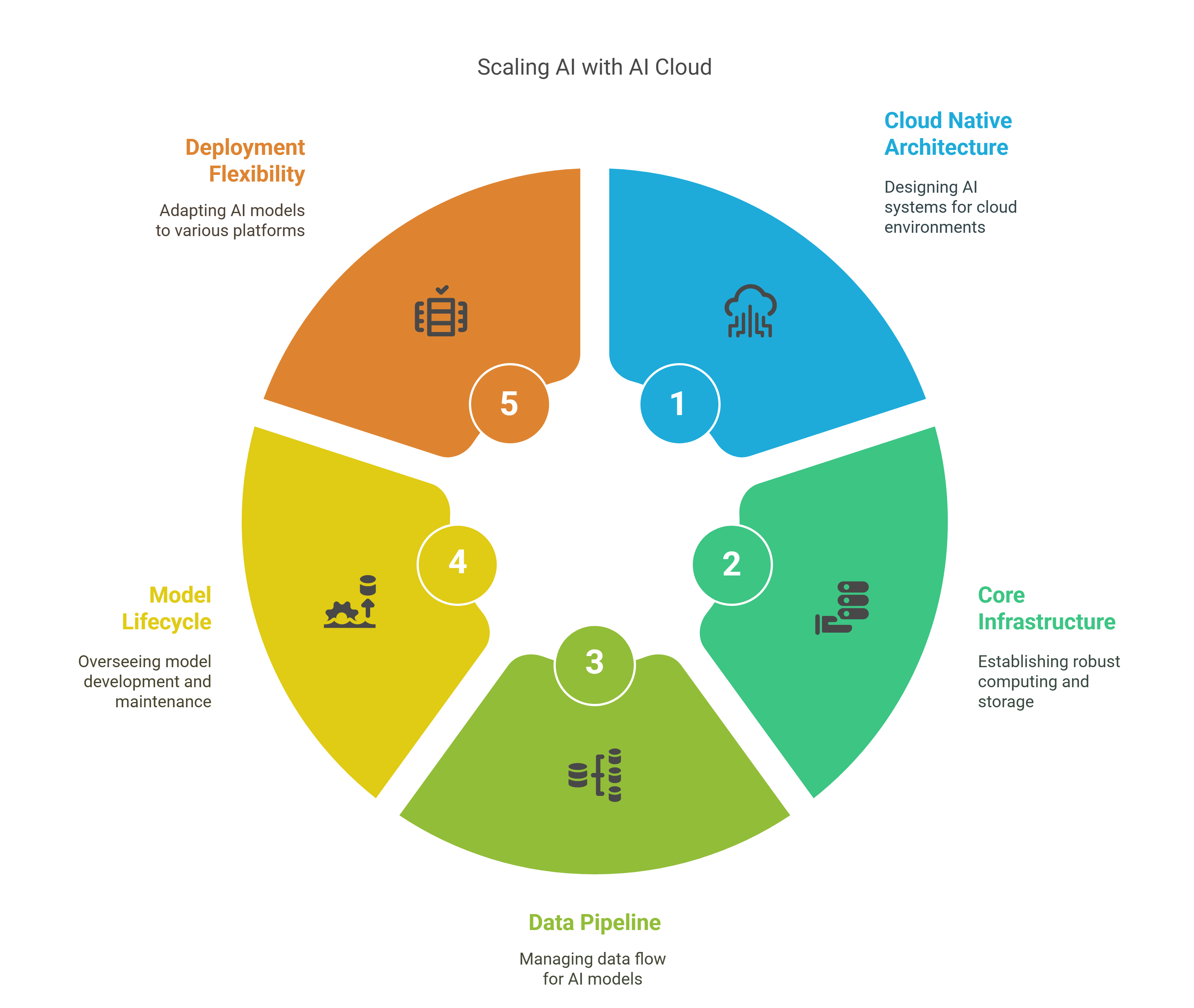
Cloud native architecture for AI scalability
In our AI cloud architecture blog post, we discussed the foundational principles, including containerization, microservices, distributed processing, and automation, and how cloud native systems enable AI workloads to be deployed and scaled effortlessly in dynamic environments. Here, we will cover this in short:
Containerization and orchestration
- Containerization technologies (e.g., Docker) package AI applications with their dependencies into a lightweight, single unit, ensuring consistent deployment across different environments.
- Orchestration tools like Kubernetes automate deployment, scaling, and management of containerized AI applications.
- Dynamic resource allocation based on demand for training jobs, inference APIs, and data processing pipelines.
Microservices architecture
- Decouples data preprocessing, model training, and inference into independently deployable services.
- Enables component-specific scaling instead of monolithic scaling.
- Supports independent scaling and iteration for each component rather than scaling the entire application monolithically.
Distributed processing and workflow management
- Frameworks like Apache Spark, Dask, Ray, and Horovod enable parallelism and resource abstraction.
- Tools like KubeFlow and MLFlow abstract the complexity of cluster management.
- Infrastructure-as-Code (IaC) solutions such as Terraform and Pulumi and GitOps tools such as ArgoCD, automate provisioning and ensure consistent deployments.
- Reduces operational complexity while maintaining scalability.
Core infrastructure scalability
Modern AI workloads exceed the capabilities of traditional infrastructure, demanding a highly specialized optimization of compute, storage, and networking to manage enormous data volumes, high concurrency, and dynamic resource requirements. Unlike traditional applications, AI workloads require large-scale parallelism, low latency data movement, accelerator supporting compute, and hardware-specific requirements to train complex models.
- Compute optimization involves optimizing accelerator utilization. Technologies such as NVIDIA Multi-Instance GPU (MIG), AMD MxGPU, and Google TPU multi-tenancy enable multiple training tasks to share GPUs and TPUs with high-granularity management. This enhances resource utilization, enables multi-tenant workflows, and minimizes costs. Auto-scaling clusters, including AWS EC2 Auto Scaling or GKE Autopilot, dynamically scale compute resources according to the intensity of the workload, delivering elasticity for model training or batch inference.
- Storage layer optimization aims to provide high IOPS and throughput at scale. Distributed object stores, such as Amazon S3, Google Cloud Storage, and Azure Blob Storage allow for thousands of nodes in parallel, whereas high-performance file systems like Lustre, BeeGFS, or GPFS (IBM’s General Parallel File System) provide low-latency, high-bandwidth I/O needed for complex training pipelines. Tiered storage approaches automatically transfer data between hot, warm, and cold storage classes for a balance between cost and performance.
- Network optimization is crucial in distributed training. Low-latency, high-bandwidth interconnects (such as NVLink, InfiniBand, or Google’s Andromeda) enable quick communication between nodes and accelerators. Load balancing and edge-to-cloud routing improve inference delivery across geographies and devices, allowing for scalable, real-time AI platforms.
Data pipeline scalability
Scaling data pipelines demands a comprehensive strategy that combines multiple approaches for effectively managing large data sets. Businesses generally implement the following strategies in combination:
- Distributed processing frameworks: AI platforms leverage distributed computing frameworks like Apache Beam, Spark, and Flink, which support parallel execution of Extract, Transform, and Load (ETL) operations across distributed nodes. They support both batch and streaming workloads, enhancing fault tolerance, resource utilization, and throughput.
- Streaming vs. batch processing: Stream processing can handle real-time data ingestion and analysis, making it ideal for fraud detection, recommendation engines, and continuous learning models, while batch processing manages large volume operations like comprehensive training models and historical analysis. Scalable AI pipelines typically leverage both approaches to balance latency, throughput, resource utilization, and cost.
- Data partitioning and parallel processing: Data partitioning, such as sharding large datasets by time, user ID, or key that distributes load across systems, increases I/O performance and allows several compute nodes to handle data concurrently. It minimizes processing time and makes the pipeline more resilient to bottlenecks. Common partitioning strategies include range, hash, and list partitioning. Tools like Dask or Petastorm further enhance parallel data loading during model training.
- Feature store optimization techniques: Feature stores offer a centralized location for scalable storage and management of ML features using platforms like Feast, Butterfree, and Hopsworks, which offer horizontally scalable feature storage and serving, whereas commercial ones like Tecton provide enterprise-grade options for production-level workloads. Optimization techniques include caching frequently accessed features, precomputing aggregations, and using key-value storage for efficient lookups.
Model lifecycle scalability
Distributed training involves training a model across multiple machines or GPUs to accelerate the training process and to reduce time and scale with model size and complexity. Orchestration tools like Horovod or PyTorch Distributed Data Parallel (DDP) facilitate model parallelism on multi-node GPU clusters. Frameworks like Ray, Kubeflow, or MLFlow assist in managing experiments, job distribution, and result tracking. It ensures minimal resource usage and quicker iteration cycles, especially with large datasets or complex models.
After training models, they need to be deployed such that they are both scalable and consistent. Effective deployment approaches include A/B testing, serverless architectures, microservices-based deployment, blue-green deployments, and canary rollouts. Implementing a proper deployment strategy enables safe, incremental model updates in production while reducing risk, enabling quick rollback when necessary, and accommodating continuous delivery in production environments.
When serving models in production, inference must scale to handle fluctuating demand. Horizontal scaling is obtained through replicating model servers (e.g., with KServe or TensorFlow Serving) across multiple nodes. Vertical scaling uses techniques like model quantization and hardware acceleration to optimize individual server performance. The appropriate strategy depends on model size, request volume, and latency requirements, with many production systems using a combination of both approaches.
As data evolves, models’ accuracy decreases over time. AI-powered retraining pipelines built on platforms like Airflow, MLFlow, Kubeflow Pipelines, or SageMaker Pipelines identify data drift or performance degradation and initiate model updates, without sacrificing performance. These pipelines automate data validation, feature generation, model retraining, evaluation, and redeployment. This facilitates continuous learning, maintaining model accuracy with minimal human intervention.
Deployment flexibility
Deployment must be flexible to ensure that AI applications are highly available, low-latency, and compliant with regulations. Multi-region deployment allows distributing AI models and services across multiple cloud regions for resilience, low latency, and traffic loads. Tools like GCP’s Global Load Balancer or AWS Global Accelerator facilitate intelligent routing to the optimal region based on user location and server health.
- Edge computing platforms such as AWS Greengrass, Azure IoT Edge, or NVIDIA Jetson enable real-time inference near data sources (e.g., in retail, manufacturing, or autonomous systems). This minimizes latency and bandwidth expenses while enhancing privacy and data control.
- Hybrid cloud models, where on-premises and cloud resources are integrated, are critical for regulated industries (e.g., finance, healthcare), latency-critical workloads, or to facilitate gradual migration from traditional systems to the cloud. Businesses often require flexible deployment across environments, such as on-premises GPU clusters for sensitive data processing and cloud burst capacity to manage peak training demands. In addition, multi-cloud strategies help avoid vendor lock-in. Tools like Anthos (Google Cloud), Azure Arc, or AWS Outposts assist in managing this configuration.
- Data compliances and regulations (i.e., GDPR, HIPAA) typically involve storing and processing data within specific geographies. Deploying AI models and pipelines to execute in particular regions or countries using region-based cloud services becomes necessary. Designing for deployment flexibility ensures that AI can scale without compromising performance, compliance, or cost-effectiveness.
How to implement AI Cloud?
Before implementing an AI cloud solution, businesses need to understand their present technical landscape. The pre-implementation process involves reviewing existing infrastructure, determining bottlenecks in existing data pipelines, evaluating compatibility with cloud-native technologies (e.g., containers, orchestration tools), and determining limitations in existing MLOps practice.
After gaps are identified, the architecture must be rebuilt with scalability-focused principles, using practices such as:
- Stateless microservices for modular components
- Event-driven processing for real-time data streams
- Horizontal scaling wherever feasible
- Infrastructure-as-Code for reproducibility and automation
- Loose coupling between systems to enable independent scaling
Migrating existing AI workloads to the cloud should be a phased and strategic process, for example, starting with low-risk workloads (e.g., batch processing or offline training) first, then containerizing applications for portability between environments, and implementing CI/CD pipelines in place to enable automated testing and deployment. Gradually, we can migrate mission-critical workloads following validation of performance and reliability.
After the migration is done, we need to ensure the success and health of scalable AI systems. For that, businesses must implement comprehensive monitoring of key performance metrics with tools such as Prometheus, Grafana, or OpenTelemetry. Typical metrics, such as throughput, latency, resource usage, and model accuracy, can be tracked over time, with automated alerts triggered when thresholds are hit using the monitoring tools.
Watch our webinar on cost-efficient AI scaling strategies, where AI experts discussed what is needed to efficiently scale AI workloads, balancing costs, infrastructure, and performance.
Final words
In this blog post, we learned how AI cloud enables scalable, flexible, and cost-effective ML at production scale. With compute elasticity, distributed storage, automated pipelines, cloud-native architecture, and global deployment options, cloud-native technologies enable AI with ease of use at scale. As infrastructure continues to evolve, trends like serverless AI, zero-trust ML, and multi-cloud optimization will continue to ease scalability. The business must ensure its infrastructure and practices are cloud-native, aligned to realize the complete potential of AI.
Ready to take the next step toward unlocking scalability with AI cloud for innovation at scale? If you’re looking for experts who can help you scale or build your AI infrastructure, reach out to our AI & GPU Cloud experts.
If you found this post valuable and informative, subscribe to our weekly newsletter for more posts like this. I’d love to hear your thoughts on this post, so do start a conversation on LinkedIn.
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like